The lifecycle of a new relay

Many people set up new fast relays and then wonder why their bandwidth is not fully loaded instantly. In this post I'll walk you through the lifecycle of a new fast non-exit relay, since Tor's bandwidth estimation and load balancing has gotten much more complicated in recent years. I should emphasize that the descriptions here are in part anecdotal — at the end of the post I ask some research questions that will help us make better sense of what's going on.
I hope this summary will be useful for relay operators. It also provides background for understanding some of the anonymity analysis research papers that people have been asking me about lately. In an upcoming blog post, I'll explain why we need to raise the guard rotation period (and what that means) to improve Tor's anonymity. [Edit: here is that blog post]
A new relay, assuming it is reliable and has plenty of bandwidth, goes through four phases: the unmeasured phase (days 0-3) where it gets roughly no use, the remote-measurement phase (days 3-8) where load starts to increase, the ramp-up guard phase (days 8-68) where load counterintuitively drops and then rises higher, and the steady-state guard phase (days 68+). 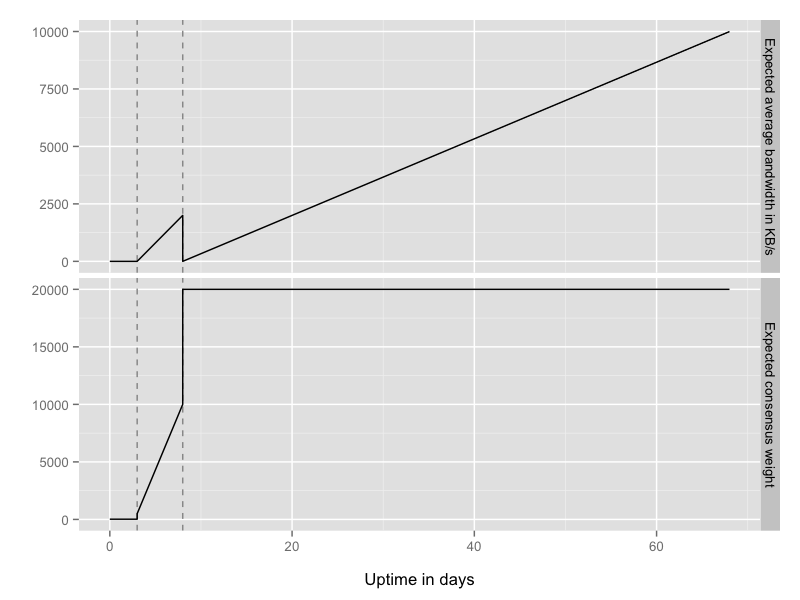 Phase one: unmeasured (days 0-3).
Phase one: unmeasured (days 0-3).
When your relay first starts, it does a bandwidth self-test: it builds four circuits into the Tor network and back to itself, and then sends 125KB over each circuit. This step bootstraps Tor's passive bandwidth measurement system, which estimates your bandwidth as the largest burst you've done over a 10 second period. So if all goes well, your first self-measurement is 4*125K/10 = 50KB/s. Your relay publishes this number in your relay descriptor.
The directory authorities list your relay in the network consensus, and clients get good performance (and balance load across the network) by choosing relays proportional to the bandwidth number listed in the consensus.
Originally, the directory authorities would just use whatever bandwidth estimate you claimed in your relay descriptor. As you can imagine, that approach made it cheap for even a small adversary to attract a lot of traffic by simply lying. In 2009, Mike Perry deployed the "bandwidth authority" scripts, where a group of fast computers around the Internet (called bwauths) do active measurements of each relay, and the directory authorities adjust the consensus bandwidth up or down depending on how the relay compares to other relays that advertise similar speeds. (Technically, we call the consensus number a "weight" rather than a bandwidth, since it's all about how your relay's number compares to the other numbers, and once we start adjusting them they aren't really bandwidths anymore.)
The bwauth approach isn't ungameable, but it's a lot better than the old design. Earlier this year we plugged another vulnerability by capping your consensus weight to 20KB until a threshold of bwauths have an opinion about your relay — otherwise there was a several-day window where we would use your claimed value because we didn't have anything better to use.
So that's phase one: your new relay gets basically no use for the first few days of its life because of the low 20KB cap, while it waits for a threshold of bwauths to measure it.
Phase two: remote measurement (days 3-8).
Remember how I said the bwauths adjust your consensus weight based on how you compare to similarly-sized relays? At the beginning of this phase your relay hasn't seen much traffic, so your peers are the other relays who haven't seen (or can't handle) much traffic. Over time though, a few clients will build circuits through your relay and push some traffic, and the passive bandwidth measurement will provide a new larger estimate. Now the bwauths will compare you to your new (faster) peers, giving you a larger consensus weight, thus driving more clients to use you, in turn raising your bandwidth estimate, and so on.
Tor clients generally make three-hop circuits (that is, paths that go through three relays). The first position in the path, called the guard relay, is special because it helps protect against a certain anonymity-breaking attack. Here's the attack: if you keep picking new paths at random, and the adversary runs a few relays, then over time the chance drops to zero that *every single path you've made* is safe from the adversary. The defense is to choose a small number of relays (called guards) and always use one of them for your first hop — either you chose wrong, and one of your guards is run by the adversary and you lose on many of your paths; or you chose right and all of your paths are safe. Read the Guard FAQ for more details.
Only stable and reliable relays can be used as guards, so no clients are willing to use your brand new relay as their first hop. And since in this story you chose to set up a non-exit relay (so you won't be the one actually making connections to external services like websites), no clients will use it as their third hop either. That means all of your relay's traffic is coming from being the second hop in circuits.
So that's phase two: once the bwauths have measured you and the directory authorities lift the 20KB cap, you'll attract more and more traffic, but it will still be limited because you'll only ever be a middle hop.
Phase three: Ramping up as a guard relay (days 8-68).
This is the point where I should introduce consensus flags. Directory authorities assign the Guard flag to relays based on three characteristics: "bandwidth" (they need to have a large enough consensus weight), "weighted fractional uptime" (they need to be working most of the time), and "time known" (to make attacks more expensive, we don't want to give the Guard flag to relays that haven't been around a while first). This last characteristic is most relevant here: on today's Tor network, you're first eligible for the Guard flag on day eight.
Clients will only be willing to pick you for their first hop if you have the "Guard" flag. But here's the catch: once you get the Guard flag, all the rest of the clients back off from using you for their middle hops, because when they see the Guard flag, they assume that you have plenty of load already from clients using you as their first hop. Now, that assumption will become true in the steady-state (that is, once enough clients have chosen you as their guard node), but counterintuitively, as soon as you get the Guard flag you'll see a dip in traffic.
Why do clients avoid using relays with the Guard flag for their middle hop? Clients look at the scarcity of guard capacity, and the scarcity of exit capacity, and proportionally avoid using relays for positions in the path that aren't scarce. That way we allocate available resources best: relays with the Exit flag are used mostly for exiting when they're scarce, and relays with the Guard flag are used mostly for entering when they're scarce.
It isn't optimal to allow this temporary dip in traffic (since we're not taking advantage of resources that you're trying to contribute), but it's a short period of time overall: clients rotate their guards nodes every 4-8 weeks, so pretty soon some of them will rotate onto your relay.
To be clear, there are two reasons why we have clients rotate their guard relays, and the reasons are two sides of the same coin: first is the above issue where new guards wouldn't see much use (since only new clients, picking their guards for the first time, would use a new guard), and second is that old established guards would accrue an ever-growing load since they'd have the traffic from all the clients that ever picked them as their guard.
One of the reasons for this blog post is to give you background so when I later explain why we need to extend the guard rotation period to many months, you'll understand why we can't just crank up the number without also changing some other parts of the system to keep up. Stay tuned for more details there, or if you don't want to wait you can read the original research questions and the followup research papers by Elahi et al and Johnson et al.
Phase four: Steady-state guard relay (days 68+).
Once your relay has been a Guard for the full guard rotation period (up to 8 weeks in Tor 0.1.1.11-alpha through 0.2.4.11-alpha, and up to 12 weeks in Tor 0.2.4.12-alpha and later), it should reach steady-state where the number of clients dropping it from their guard list balances the number of clients adding it to their guard list.
Research question: what do these phases look like with real-world data?
All of the above explanations, including the graphs, are just based on anecdotes from relay operators and from ad hoc examination of consensus weights.
Here's a great class project or thesis topic: using our publically available Tor network metrics data, track the growth pattern of consensus weights and bandwidth load for new relays. Do they match the phases I've described here? Are the changes inside a given phase linear like in the graphs above, or do they follow some other curve?
Are there trends over time, e.g. it used to take less time to ramp up? How long are the phases in reality — for example, does it really take three days before the bwauths have a measurement for new relays?
How does the scarcity of Guard or Exit capacity influence the curves or trends? For example, when guard capacity is less scarce, we expect the traffic dip at the beginning of phase three to be less pronounced.
How different were things before we added the 20KB cap in the first phase, or before we did remote measurements at all?
Are the phases, trends, or curves different for exit relays than for non-exit relays?
The "steady-state" phase assumes a constant number of Tor users: in situations where many new users appear (like the botnet invasion in August 2013), current guards will get unbalanced. How quickly and smoothly does the network rebalance as clients shift guards after that?
Comments
Please note that the comment area below has been archived.
As "fast" is nowadays not
As "fast" is nowadays not defined as 20k/s+ but 100k/s+ - is running a slower relay worthwhile or do the control and measurement connections stress the whole network even more?
Running a relay with less
Running a relay with less than 100KBytes/s is probably not helpful -- at that point you should be running a bridge instead:
https://www.torproject.org/docs/faq#RelayOrBridge
It's actually not about stressing the network with tests. It's about the crummy performance users will get if they happen to pick a really slow relay. It's an open research question where the right cutoff should be, but some researchers think it should be as high as 1MByte/s. That's probably a poor choice for community reasons, and maybe for diversity reasons as well, but it helps to illustrate the battle between anonymity and performance. See this ticket for many more details:
https://trac.torproject.org/projects/tor/ticket/1854
thanks for the detailed
thanks for the detailed answer - so I should downgrade my 50k/s-relay 2 days announcing as relay again :)
the bandwidth requirement has imho one huge disadvantage: donating DSL bandwidth to the Tor network has/had a low threshold, but 100k/s+ in both directions isn't in the typical (DSL) consumer range anymore and leads to centralization (like donating to torservers.net instead of running a relay)
Yep. That centralization is
Yep. That centralization is also a big factor when you consider bandwidth pricing.
There is some hope for the future, though there's a lot of research and engineering work to be done first -- check out the Conflux design:
http://freehaven.net/anonbib/#pets13-splitting
The basic idea is to build several circuits in parallel and glue them together.
regarding bridge/relay: do
regarding bridge/relay: do you have plans to distribute Obfsproxy not only via your .deb-repositories but also for RPM-based distributions?
Not that I know of.
Not that I know of. Volunteers?
If a relay goes into
If a relay goes into hibernation, does it start at "day 0" when waking up? The "not in the cached consensus" message seems to imply something like this.
Great question. It really
Great question. It really depends what the bwauths do with old measurements. They might pick up right where they left off, or they might get confused. I think nobody has studied this -- it's a great addition to the research questions at the end.
Why is it that bridge nodes,
Why is it that bridge nodes, which act as guards, are not subject to the same standards as regular guard nodes?
Because if you need a bridge
Because if you need a bridge we figure you'd rather have some connectivity than no connectivity.
You're absolutely right to wonder if there are performance implications to having slower bridges as your first hop. Or if there are anonymity implications from choosing your first hop in a different way.
These are both good research questions.
When does the Directory flag
When does the Directory flag get set and how does it affect bandwidth?
There is no Directory flag.
There is no Directory flag. Maybe you mean the V2Dir flag?
https://gitweb.torproject.org/torspec.git/blob/HEAD:/dir-spec.txt#l1782
That's a great point -- relays with open directory ports will serve directory information too, and maybe that will influence the duration or variance in their bootstrapping phases.
My guess is that it's not a huge influence though, since the bandwidth measurements are bidirectional whereas serving directory information is unidirectional.
Now that we see new rc
Now that we see new rc versions coming out, how do I keep my server flagged as stable during update? I do keep my secret_id_key and my profile name, but restarting new relay always puts uptime back to zero....
Don't worry about it. Just
Don't worry about it. Just minimize the length of downtime and its frequency, and people should still connect back to you. I just learned on the mailing list that it's the fraction of total time that you're is the measurement that counts. You have to restart Tor in order to upgrade, there's no way around that. They wouldn't recommend upgrading if restarting Tor was a terrible thing.
Right. Whether you have or
Right. Whether you have or don't have a given flag shouldn't matter very much. Just run a fine (including up-to-date) relay and let Tor take care or where the relay should be best used. Thanks for helping out!
Is there a bandwidth rate
Is there a bandwidth rate below which it is better to not be a dir server?
I'm running a fairly new relay (a bit over a week now) that advertises and handles 1Mbit (128MByte) and I feel that serving directory traffic, which is upload only, takes quite a chunk out of Tor traffic. It causes the relay to use more upload than download, while most people have more download to spare than upload.
(I realize this story is really about fast relays. Sorry if this is off-topic.)
Are exit relays on
Are exit relays on residential DSL service with bandwidth between 20K and 50K helpful to the network?
Good question. I'd say it's
Good question. I'd say it's in the grey area -- we need exit relays, but that isn't very much bandwidth.
I guess the way to phrase that as a research question here is: historically, have exit relays of this size managed to attract much traffic?
my former exit with 40k/s
my former exit with 40k/s was used to capacity 24/7 - though this was in 2007-2009
My exit is rate limited to
My exit is rate limited to 24Kb. If I allow a higher rate, it interferes with other devices on the line, especially VOIP. I generally see 1-2GB combined traffic per day at this rate. Is this a useful contribution?
Is there a best practices
Is there a best practices guide on setting up a relay? I've read a bunch of docs but what are the recommended CPU/memory requirements? I'm planning on setting up a 100k/s relay and need to know the hardware I will need. Is Debian a good choice? I will run 0.2.4.
Fetch the Tor Browser
Fetch the Tor Browser Bundle, extract it, use the GUI to configure it as a relay, and then just leave it alone. All should be well. At least that's the way I did it, and I'm running it on my personal computer under Linux Mint. It's bandwidth that's the most important factor: CPU power isn't extremely important unless you're shoving a huge volume of cryptographically-secured data through, which at that speed you aren't. If you don't have a really low-end CPU, you should be fine. Tor should tell you if your machine can't keep up, then you'll know. Debian should be fine.
Actually, this isn't great
Actually, this isn't great advice for Linux users. The much better answer if you want to run a relay is to install the Tor package (e.g. deb) and configure it.
The deb has a variety fo features to make your relay better -- it starts it as a new separate user, it starts it at boot, it changes the number of file descriptors it's allowed to use, etc. Relays started under Vidalia don't have those features, and for anything more than tiny relays they make a big difference.
https://www.torproject.org/docs/tor-relay-debian
Hey I think you need this
Hey I think you need this info :)
http://www.321linux.com/2014/02/23/tor-relay-unter-debian-gnulinux-bei-…
Great explanation of how
Great explanation of how relays work, arma! I found this article easy to understand, and very informative.
I nominate this article for addition to the document or wiki section on torproject.org, so it doesn't get lost to time.
The time frames are a bit
The time frames are a bit off - my new relay got 100% use within 1.5 days - but otherwise a very thought provoking article. What it basically says is 'Set up a cron job to kill/restart Tor once a week - if you want the network to use as much of your bandwidth as possible'
I'm tempted to set myself up as a bridge instead to see how much use I would get. It can't hurt the cause to throw some bw that way! My only concern now is that the IP of the relay already could have been put in a block list. Damn, should have read up on relay vs bridge beforehand, and _thought_ about it.
The advice in https://www.torproject.org/docs/faq.html.en#RelayOrBridge is oversimplified...
verb
past tense: oversimplified; past participle: oversimplified
1.
simplify (something) so much that a distorted impression of it is given.
> 'Set up a cron job to
> 'Set up a cron job to kill/restart Tor once a week - if you want the network to use as much of your bandwidth as possible'
No! This is not what I meant to imply. See how the bandwidth load graph goes way higher in phases three and four than it does in phase two? If you try to avoid getting the Guard flag, you'll only ever get used as a middle hop. Once you get the Guard flag, you can be used as either.
Also, avoiding the Guard flag means you don't contribute to the diversity of entry points in the network, which is a key part of Tor's anonymity:
https://blog.torproject.org/blog/research-problem-better-guard-rotation…
I want to update my VPS tor
I want to update my VPS tor relay to the latest build but that will cause it to restart. If it restarts, won't I lose some of the flags I've acquired since the server has been online for 21 days?
Updating is usually a good
Updating is usually a good idea. Don't worry too much about which flags you have or don't have yet.
Where could I get the data
Where could I get the data that when a certain relay appear and its WPU? Could I get these data from Tor network metrics data?
Perhaps you mean WFU. Some
Perhaps you mean WFU.
Some of this data is available on metrics.torproject.org yes. Others, maybe you need to write a patch to help us collect and archive it.
Heh... I had a "grep" with
Heh... I had a "grep" with timestamps running on the flags, and after 10 days and 1 hour the relay got a Guard flag. The load did not ease at all, 100% use of the bandwidth. Two hours later the flag was gone! Perhaps some human is fiddling with the directory authorities ;-)
Or perhaps you're right on
Or perhaps you're right on the borderline of one of the thresholds.
How much bandwidth does your relay have?
(Even better, point us to the atlas.torproject.org url for it.)
That's a nifty
That's a nifty url:
https://atlas.torproject.org/#details/AB6DE5CCD9C542809FE78E60528549D7C…
The first five days it ran with a 750 KByte limit, but when I saw your comment: "It's an open research question where the right cutoff should be, but some researchers think it should be as high as 1MByte/s" I upped it to 1.1MBytes.
Something was shook loose at
Something was shook loose at the authorities and my relay got a Guard flag after 10 days and 18 hours, or so. First seen in a 13:12 saved cached-microdesc-consensus. But now four hours later the load has gotten even worse. Half a million TAP handshakes is something I've never seen before.
A paranoid thought, since the NTors are dropping, is that the botnet disregards a Guard flag, or even actively seeks it out...
Sep 17 13:07:20.728 [Notice] Circuit handshake stats since last time: 379938/379949 TAP, 348/348 NTor.
Sep 17 14:07:20.732 [Notice] Circuit handshake stats since last time: 476860/476954 TAP, 319/319 NTor.
Sep 17 15:07:20.729 [Notice] Circuit handshake stats since last time: 473187/473219 TAP, 170/170 NTor.
Sep 17 16:07:20.731 [Notice] Circuit handshake stats since last time: 512643/512707 TAP, 126/126 NTor.
Sep 17 17:07:20.735 [Notice] Circuit handshake stats since last time: 527063/527133 TAP, 113/113 NTor.
Clients use CREATE_FAST
Clients use CREATE_FAST cells when establishing the first hop with the entry guard, so those won't be counted in either the TAP or the NTor statistics.
(I decided not to count create_fasts in the stast, because then we're counting and logging something to do with how many users of which version are connecting to that entry guard, and that raises complex anonymity questions.)
Hi arma, sorry for
Hi arma,
sorry for off-topic, i don't know how to contact you elsewhere :(
i've got a question concerning the security of older tor traffic before the update to version 2.4, when the tor handshake was based on DH 1024. It is lately disussed that the NSA is maybe able to decrypt DH 1024 with reasonable time and cost efficiency (http://techcrunch.com/2013/09/07/the-nsa-can-read-some-encrypted-tor-tr…). It is also well known that most encrypted internet traffic, included tor traffic, is recorded and stored for unlimited time. So i guess, if not today, there will come the time when they would be able to decrypt those records.
I'm not an expert and it gets confusing here. What i would like to know is: Does this mean that it's just a matter of time until all traffic run over tor (and recorded by those agencies) in the last years would be readable to them? Does it also mean that our IPs and identities will be revealed? Or am i getting this wrong?
There's a whole blog post
There's a whole blog post full of confused and worried people, just for you:
https://blog.torproject.org/blog/tor-nsa-gchq-and-quick-ant-speculation
As for how to contact us,
https://www.torproject.org/about/contact
http://i.imgur.com/0BPAgT2.pn
http://i.imgur.com/0BPAgT2.png
I created a new relay today :)
How does the relay schedule
How does the relay schedule the circuits that goes through the relay? I mean how the relay allocates its bandwidth to multiple circuits? If it works in an unfair manner, will the scheduling scheme affect the measurement of the relay's capacity?
All good questions. See
All good questions. See these research papers for a start:
http://freehaven.net/anonbib/#ccs10-braids
http://freehaven.net/anonbib/#throttling-sec12
http://freehaven.net/anonbib/#pets13-how-low
3 days + 5 days + 60 days of
3 days + 5 days + 60 days of continuous or discontinuous uptime?
It doesn't have to be
It doesn't have to be continuous. But if you're down during some of the bandwidth tests, I bet things won't proceed with the timeframes described in the post. This is a fine research question -- somebody should look at the data, find some relays that were down for some fraction of some of these phases, and see how much the results change for those.
Can't wait to get the Guard
Can't wait to get the Guard flag! I'm starting day eight and already have "Fast, HSDir, Running, Stable, V2Dir, Valid". It feels like Pokemon, gotta catch em all!
Speaking of gamification,
Speaking of gamification, see
https://lists.torproject.org/pipermail/tor-dev/2014-July/007181.html
I'm running a new relay (up
I'm running a new relay (up ~72 hours). The relay's log shows that the self-test passed, `arm' reports flags={Fast, Running, Valid}, total Uploaded and Downloaded data are a little over 2 GB each (a bit < 200 Kb/sec avg). An email from Tor-weather reports that data is getting through, albeit much less than advertised bandwidth (not surprising given this article). Why is globe.torproject.org showing "No data available in table" for my relay (I tried searching by hash key and nickname)?
Good question. I think
Good question. I think something is wrong with onionoo currently -- perhaps it is not getting updates. Karsten is on vacation currently, but he'll be back soon I think.
Same issue here, tor relay
Same issue here, tor relay with "flags: Exit, Fast, Running, Valid" on arm, tor log shows: "Tor's uptime is 1 day 12:00 hours, with 21 circuits open. I've sent 6.81 GB and received 6.93 GB.".. but doesn't appear on globe :(
Try
Try http://torstatus.blutmagie.de/