Browser Fingerprinting: An Introduction and the Challenges Ahead

Guest post by Pierre Laperdrix
In the past few years, a technique called browser fingerprinting has received a lot of attention because of the risks it can pose to privacy. What is it? How is it used? What is Tor Browser doing against it? In this blog post, I’m here to answer these questions. Let’s get started!
What is browser fingerprinting?
Since the very beginning of the web, browsers did not behave the exact same way when presented with the same webpage: some elements could be rendered improperly, they could be positioned at the wrong location or the overall page could simply be broken with an incorrect HTML tag. To remedy this problem, browsers started including the “user agent” header. This informed the server on the browser being used so that it could send the device a page that was optimized for it. In the nineties, this started the infamous era of the “Best on IE” or “Optimized for Netscape.”
In 2019, the user-agent header is still here but a lot has changed since then. The web as a platform is a lot richer in terms of features. We can listen to music, watch videos, have real-time communications or immerse ourselves in virtual reality. We can also use a very wide variety of devices from tablets, smartphones or laptops to connect to it. To offer an experience that is optimized for every device and usage, there is still a need today to share configuration information with the server. “Here is my timezone so that I can know the exact start time of the NBA finals. Here is my platform so that the website can give me the right version of the software I’m interested in. Here is the model of my graphic card so that the game I’m playing in my browser can chose graphic settings for me.”
All of this makes the web a truly beautiful platform as it enables us to have a comfortable experience browsing it. However, all that information that is freely available to optimize the user experience can be collected to build a browser fingerprint.
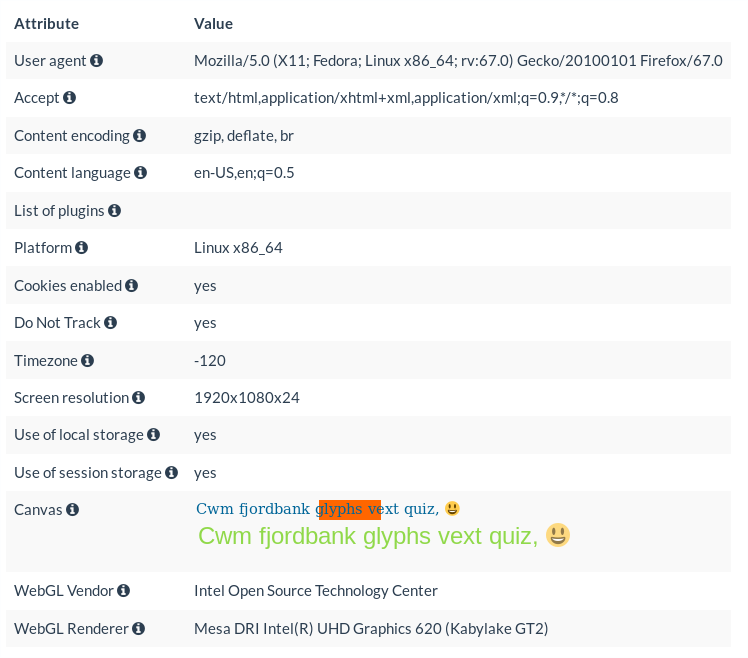
Figure 1: Example of a browser fingerprint from a Linux laptop running Firefox 67
In Figure 1, you can see a browser fingerprint taken from my Linux laptop. The information in the fingerprint was collected via HTTP with the received HTTP headers and via JavaScript by running a small script. The “user-agent” indicates that the user was using Firefox version 67 on the Fedora Linux distribution. The “content-language” header indicates that the user wants to receive her page in English with the “US” variant. The “-120” for the timezone refers to the GMT+2 time. Finally, the WebGL renderer gives information on the CPU of the device. Here, the laptop is using an Intel CPU with a Kaby Lake Refresh microarchitecture.
This example is a glimpse of what can be collected in a fingerprint and the exact list is evolving over time as new APIs are introduced and others are modified. If you want to see your own browser fingerprint, I invite you to visit AmIUnique.org. It is a website that I launched in 2014 to study browser fingerprinting. With the data that we collected from more than a million visitors, we got invaluable insight into its inner-workings and we pushed the research in the domain forward.
What makes fingerprinting a threat to online privacy?
It is pretty simple. First, there is no need to ask for permissions to collect all this information. Any script running in your browser can silently build a fingerprint of your device without you even knowing about it. Second, if one attribute of your browser fingerprint is unique or if the combination of several attributes is unique, your device can be identified and tracked online. In that case, no need for a cookie with an ID in it, the fingerprint is enough. Hopefully, as we will see in the next sections, a lot of progress have been made to prevent users from having unique values in their fingerprint and thus, avoid tracking.
Tor + Fingerprinting
Tor Browser was the very first browser to address the problems posed by fingerprinting as soon as 2007, even before the term “browser fingerprinting” was coined. In March 2007, the changelog for the Tor button indicated the inclusion of Javascript hooking to mask timezone for Date Object.
In the end, the approach chosen by Tor developers is simple: all Tor users should have the exact same fingerprint. No matter what device or operating system you are using, your browser fingerprint should be the same as any device running Tor Browser (more details can be found in the Tor design document).
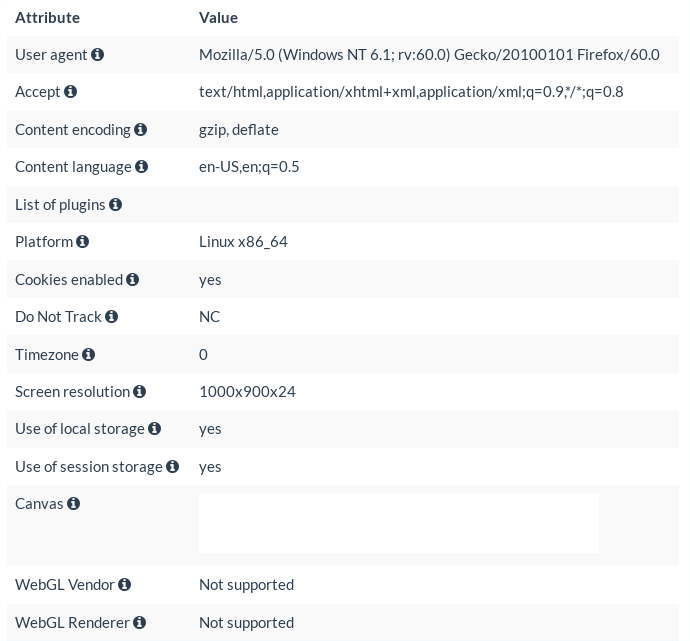
Figure 2: Example of a browser fingerprint from a Linux laptop running Tor Browser 8.5.3
In Figure 2, you can find the fingerprint of my Linux machine running version 8.5.3 of the Tor Browser.
Comparing with the one from Firefox, we can see notable differences. First, no mater on which OS Tor Browser is running, you will always have the following user-agent:
Mozilla/5.0 (Windows NT 6.1; rv:60.0) Gecko/20100101 Firefox/60.0
As Windows is the most widespread OS on the planet, TBB masks the underlying OS by claiming it is running on a Windows machine. Firefox 60 refers to the ESR version on which TBB is based on.
Other visible changes include the platform, the timezone, and the screen resolution.
Also, you may have wondered why the following message appears when you maximize the browser window (see Figure 3): “Maximizing Tor Browser can allow websites to determine your monitor size, which can be used to track you. We recommend that you leave Tor Browser windows in their original default size.”
This is because of fingerprinting. Since users have different screen sizes, one way of making sure that no differences are observable is to have everyone use the same window size. If you maximize the browser window, you may end up as being the only one using Tor Browser at this specific resolution and so comes a higher identification risk online.


Figure 3: Warning from the Tor Browser when maximizing the browser window
Under the hood, a lot more modifications have been performed to reduce differences between users. Default fallback fonts have been introduced to mitigate font and canvas fingerprinting. WebGL and the Canvas API are blocked by default to prevent stealthy collection of renderings. Functions like performance.now have also been modified to prevent timing operations in the browser that can be used for micro-architectural attacks. If you want to see all the efforts made by the Tor team behind the scenes, you can take a look at the fingerprinting tag in the bug tracker. A lot of work is being done to make this a reality. As part of the effort to reduce fingerprinting, I also developed a fingerprinting website called FP Central to help Tor developers find fingerprint regressions between different Tor builds.
Finally, more and more modifications present in TBB are making their way into Firefox as part of the Tor Uplift program.
Where we are
Over the past few years, research on browser fingerprinting has substantially increased and covers many aspects of the domain. Here, we will have a quick overview of the research done in academia and how fingerprinting is used in the industry.
Academic research
1. Tracking with fingerprinting is a reality but it cannot replace different tracking schemes based on identifiers. Different studies have been published over the years trying to assess the diversity of modern devices connected on the web [1,2]. One study that I was part of in 2018 [3] surprised us as it showed that tracking at a very large scale may not be feasible with low percentage of uniqueness. Anyhow, the one clear takeaway from these studies is the following: even though some browser vendors are working very hard to reduce as much as possible the differences between devices, it is not a perfect process. If you have that one value in your browser fingerprint (or a combination) that nobody has, you can still be tracked and that is why you should be careful about fingerprinting. There is no strong guarantee today that your device is identical to another one present on the Internet.
2. As the web is getting richer, new APIs make their way into browsers and new fingerprinting techniques are discovered. The most recent techniques include WebGL [4,5], Web Audio [6] and extension fingerprinting [7,8]. To provide protection for users, it is important to keep a close watch on any new advances in the field to fix any issues that may arise.
One lesson learned from the past concerns the BatteryStatus API. It was added to provide information about the state of the battery to developers so that they could develop energy-efficient applications. Drafted as early as 2011, it was not until 2015 that researchers discovered that this API could be misused to create a short-term identifier [9,10]. In the end, this was a reminder that we have to be very thoughtful when introducing a new API in a browser. A deep analysis must be conducted to remove or mitigate as much as possible hidden fingerprinting vectors before they are deployed to end-users. To provide guidance for Web specification authors, the W3C has written a document on how best to design an API while considering fingerprinting risks

Figure 4: Example of a WebGL rendering as tested on http://uniquemachine.org/
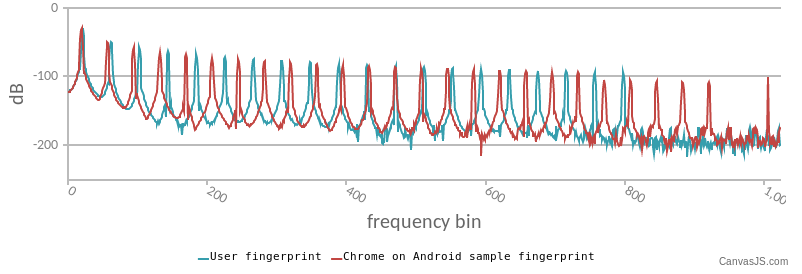
Figure 5: Example of an audio fingerprint as tested on https://audiofingerprint.openwpm.com/
3. Today, there is no ultimate solution to fix browser fingerprinting. As its origin is rooted in the beginning of the internet, there is no single patch that can fix it for good. And as such, designing defenses is hard. A lot of approaches have been tried and evaluated over the years with each their strengths and weakness. Examples include blocking attributes, introducing noise, modifying values, or increasing fingerprint diversity. However, one important observation that has been made is that sometimes having no specific defense is better than having one. Some solutions, because of the way they were designed or coded, remove some fingerprinting vectors but introduce some artifacts or inconsistencies in the collected fingerprints.
For example, imagine a browser extension that changes the value of fingerprints before they are sent.
Everything works perfectly except the fact that the developer forgot to override the navigator.platform value. Because of this, the user-agent may say that the browser is running on Windows whereas the platform still indicates it is on a Linux system. This creates a fingerprint that is not supposed to exist in reality and, as such, make the user more visible online. It is what Eckersley [1] called the “Paradox of Fingerprintable Privacy Enhancing Technologies.” By wanting to increase online privacy, you install extensions that in the end make you even more visible than before.
Industry
1. To identify websites who use browser fingerprinting, one can simply turn to privacy policies. Most of the time, you will never see the term “fingerprinting” in it but sentences along the lines of “we collect device-specific information to improve our services.” The exact list of collected attributes is often imprecise and the exact use of that information can be very opaque ranging from analytics to security to marketing or advertising.
Another way of identifying websites using fingerprinting is to look directly at the scripts that run in the browser. The problem here is that it can be challenging to differentiate a benign script that is here to improve the user experience from a fingerprinting one. For example, if a site accesses your screen resolution, is it to adjust the size of HTML elements to your screen or is it the first step in building a fingerprint of your device? The line between the two can be very thin and identifying fingerprinting scripts with precision is still a subject that has not been properly studied yet.
2. One use of fingerprinting that is lesser known is for bot detection. To secure their websites, some companies rely on online services to assess the risk associated with external connections. In the past, most decisions to block or accept a connection was purely based on IP reputation. Now, browser fingerprinting is used to go further to detect tampering or identify signs of automation. Examples of companies that use fingerprinting for this purpose include ThreatMetrix, Distil Networks, MaxMind, PerimeterX, and DataDome.
3. On the defensive side, more and more browser vendors are adding fingerprinting protection directly in their browser. As mentioned previously in this blog post, Tor and Firefox are at the forefront of these efforts by limiting passive fingerprinting and blocking active fingerprinting vectors.
Since its initial release, the Brave browser also includes built-in protection against it.
Apple made changes to Safari in 2018 to limit it and Google announced in May 2019 its intention to do the same for Chrome.
Conclusion: What lies ahead
Browser fingerprinting has grown a lot over the past few years. As this technique is closely tied to browser technology, its evolution is hard to predict but its usage is currently shifting. What we once thought could replace cookies as the ultimate tracking technique is simply not true. Recent studies show that, while it can be used to identify some devices, it cannot track the mass of users browsing the web daily. Instead, fingerprinting is now being used to improve security. More and more companies find value in it to go beyond traditional IP analysis. They analyze the content of fingerprints to identify bots or attackers and block unwanted access to online systems and accounts.
One big challenge surrounding fingerprinting that is yet to be solved is around the regulation of its usage. For cookies, it is simple to check if a cookie was set by a specific website. Anyone can go in the browser preferences and check the cookie storage. For fingerprinting, it is a different story. There is no straightforward way to detect fingerprinting attempts and there are no mechanisms in a browser to completely block its usage. From a legal perspective, this is very problematic as regulators will need to find new ways to cooperate with companies to make sure that the privacy of users is respected.
Finally, to finish this post, is fingerprinting here to stay? In the near future at least, yes. This technique is so rooted in mechanisms that exist since the beginning of the web that it is very complex to get rid of it. It is one thing to remove differences between users as much as possible. It is a completely different one to remove device-specific information altogether. Only time will tell how fingerprinting will change in the coming years but its evolution is something to watch closely as the frantic pace of web development will surely bring a lot of surprises along the way.
Thanks a lot for reading this post all the way through! If you want to dive even deeper in the subject, I invite you to read the survey [11] on the topic that we recently made available online. If by any chance you find any new fingerprinting vectors in Tor Browser, I strongly suggest that you open a ticket on the Tor bug tracker to help the fantastic efforts made by the Tor dev team to better protect users’ online anonymity!
**Pierre Laperdrix**
https://plaperdr.github.io/
Twitter: https://twitter.com/RockPartridge
References
[1] P. Eckersley. “How unique is your web browser?”. In International Symposium on Privacy Enhancing Technologies Symposium (PETS’10). [[PDF]](https://panopticlick.eff.org/static/browser-uniqueness.pdf)
[2] P. Laperdrix, W. Rudametkin and B. Baudry. “Beauty and the Beast: Diverting Modern Web Browsers to Build Unique Browser Fingerprints”. In IEEE Symposium on Security and Privacy (S&P’16).
[[PDF]](https://hal.inria.fr/hal-01285470v2/document)
[3] A. Gómez-Boix, P. Laperdrix, and B. Baudry. “Hiding in the Crowd: an Analysis of the Effectiveness of Browser Fingerprinting at Large Scale”. In The Web Conference 2018 (WWW’18). [PDF]
[4] K. Mowery, and H. Shacham. “Pixel perfect: Fingerprinting canvas in HTML5”. In Web 2.0 Security & Privacy (W2SP’12). [PDF]
[5] Y. Cao, S. Li, and E. Wijmans. “(Cross-) Browser Fingerprinting via OS and Hardware Level Features”. In Network and Distributed System Security Symposium (NDSS’17). [PDF]
[6] S. Englehardt, and A. Narayanan. “Online tracking: A 1-million-site measurement and analysis”. In ACM SIGSAC Conference on Computer and Communications Security (CCS’16). [PDF]
[7] A. Sjösten, S. Van Acker, and A. Sabelfeld. “Discovering Browser Extensions via Web Accessible
Resources”. In ACM on Conference on Data and Application Security and Privacy (CODASPY’17). [PDF]
[8] O. Starov, and N. Nikiforakis. “XHOUND: Quantifying the Fingerprintability of Browser Extensions”. In IEEE Symposium on Security and Privacy (S&P’17). [PDF]
[9] Ł. Olejnik, G. Acar, C. Castelluccia, and C. Diaz. “The Leaking Battery”. In International Workshop on Data Privacy Management (DPM’15). [PDF]
[10] Ł. Olejnik, S. Englehardt, and A. Narayanan. “Battery Status Not Included: Assessing Privacy in
Web Standards”. In International Workshop on Privacy Engineering (IWPE’17). [PDF]
[11] P. Laperdrix, N. Bielova, B. Baudry, and G. Avoine. “Browser Fingerprinting: A survey”. [PDF - Preprint]
Comments
Please note that the comment area below has been archived.
Some solutions, because of…
Yet that's precisely what Tor Browser has been doing for some time now, despite the strong backlash from users. Here's what AmIUnique says:
HTTP headers attributes
User agent: Mozilla/5.0 (Windows NT 6.1; rv:60.0) Gecko/20100101 Firefox/60.0
Javascript attributes
User agent: Mozilla/5.0 (X11; Linux x86_64; rv:60.0) Gecko/20100101 Firefox/60.0
Platform: Linux x86_64
That's true. However, the…
That's true. However, the example was that some random user installs the extension and is now suddenly standing out even though they thought they would enhance their privacy. The Tor Browser case is different in that it is not just a single user behaving that way but all of the Tor Browser Linux users which should give cover against getting singled out.
Ideally, we would spood the JavaScript attributes as well, I agree. But there are usability concerns mostly on macOS that lead us to the current solution.
Someone using Tor Browser is…
Someone using Tor Browser is already willing to sacrifice usability for privacy, in many cases to much more extreme extent than not having websites detect their OS. For example, many websites become inaccessible, either the request is directly rejected or indirectly via infinite captchas. Having to manually choose or hunt down proper OS version when doing something OS specific is a minuscule issue in comparison, as well as much more infrequent for most users.
You could anonymize those Javascript attributes only at Safer security level where the user is more willing to sacrifice usability, or fully anonymize them at all security levels except for macOS builds, or a combination of both (Standard security level + macOS build = no anonymization).
The security slider is for…
The security slider is for defenses against browser exploits: just for raising your *security* as a trade-off against functionality. We should not put *privacy* features in that mix as the result is hard to analyze and confusing to users. So, that's not a good option.
I urge Tor Project to…
I urge Tor Project to reassess these judgments in view of the latest revelations about dragnet attacks on a significant percentage of the (so far) living human population, this time apparently by China, together with the mounds of evidence that NSA is hardly a reformed character when it comes to their own vast "collect it all" dragnet surveillance programs.
Specifically, it should be clear that those users who tried to warn for years that everyone is a target have been correct all along. Which is obviously a crucial insight for making good decisions about trading off security viz. usability.
The most dangerous situations, wrt oppressive governments (and increasingly, they are all oppressive to one degree or another) arise when people falsely assume they enjoy protection, for example because they assume (falsely) that "ordinary citizens" are not targeted, or will not suffer dire consequences if a state-sponsored attack succeeds in trojaning their device.
> Someone using Tor Browser…
> Someone using Tor Browser is already willing to sacrifice usability for privacy, in many cases to much more extreme extent than not having websites detect their OS. For example, many websites become inaccessible, either the request is directly rejected or indirectly via infinite captchas.
You probably mean to say "Some Tor Browser users are willing...", but just to clear: I am one who thinks JS should be disabled by default and I tend to avoid sites which require it. If I do visit such a site, I use a different browser session. And I almost never try to use sites which demand that I fill in a captcha.
"I am one who.." is…
"I am one who.." is rethinking what I wrote just above after reading what gk said above about the distinction between security enhanscements and privacy enhancements :-)
Which begs the question: why…
Which begs the question: why not implement the JS spoofing for all versions of TB but the MacOS version?
If that is not practical, why not? And in that case, does the number of Mac OS users who use TB really justify the risk to everyone else?
Then why not use the same UA…
Then why not use the same UA ( "Mozilla/5.0 (X11; Linux x86_64; rv:60.0) Gecko/20100101 Firefox/60.0" in the previous post) both in the http header and in the JS attribute ?
It's not Linux system, you…
The term "Linux system" is totally wrong, you should use the term GNU/Linux. GNU/Hurd based on Hurd, Hurd is based on Mach.
Loyal to a fault, I grab the…
Loyal to a fault, I grab the opportunity to thank Richard Stallman and Linus Torvalds for their positive contributions to the welfare of all humans.
Why is do not track not set…
Why is Do Not Track not set in Tor Browser's HTTP headers by default?
Because it's only saying …
Because it's only saying "Dear website, please, please don't track me" where the website owner can still ignore that and track someone as they want. We want privacy by design where we don't have to beg anyone for that. Thus, Do Not Track is not helpful and we just don't use/send it.
Since I am one of those who…
Since I am one of those who criticize certain design decisions by Tor devs, I should perhaps say that this is one I happen to agree with.
"Do not track" seemed like a good idea many years ago, but it has been clear from years that it cannot possibly ever work. And I'd suggest to anyone who wants to send the message to Silicon Valley that they desire or even demand that their privacy be respected, I think that's the right attitude, but is better achieved by using Tor Browser, which sends *two* messages: I demand that Silicon Valley respect my privacy, and I am sufficiently serious about that to use the best available privacy-enhancing tool currently available, which is Tor Browser.
When I used Tor in 2017, Tor…
When I used Tor in 2017, Tor connects 3 hops that are in the same country. Can you fix it?
Tor Project cannot fix…
Tor Project cannot fix anything after it has happened, unfortunately. But you probably meant to ask whether a problem you experienced in 2017 has been addressed, and to the best of my knowledge, a good deal of attention has been paid in recent years (owing in great part to vociferous user complaints!) to the issue of node geolocation, not just at the level of country but more importantly to the problem of two or more nodes which are physically located in same server farm (for example a specific sever for hire facility in Amsterdam). AFAIK this remains a work in progress but I'd be happy to hear something from TP about the state of the art of node geolocation diversity.
Node location is less…
Node location is less concerning than if padding and timing of packets were not made to appear similar, but they are. And nodes are shared by many users simultaneously, and each domain you visit goes through a different circuit. Many defenses are working in concert. However, nodes could run compromised software that negates some defenses. The effect of those nodes could be suppressed, among other methods, by the directory servers doing more authentication of node software or by making sure country + AS (autonomous system) do not overlap for the three nodes chosen to build a circuit. But if you limit yourself from large groups of nodes as you build circuits, you affect other statistics of identifying your traffic. Tor benefits from more diversity in general. Nodes in particular are sparse in Asia, Africa and South America, and node operators can find a list of tor-friendly and unfriendly ISPs/CDNs on the Trac wiki.
Great article. Hopefully…
Great article. Hopefully that will help the letterboxing naysayers understand a bit better.
What means "letterboxing"?
What means "letterboxing"?
Letterboxing is black bars…
Letterboxing is black bars around video or images to fit in a different sized display. You will see it in Tor Browser soon because it helps to impede browser fingerprinting that detects your window resolution numbers.
https://en.wikipedia.org/wiki/Letterboxing_(filming)
https://en.wikipedia.org/wiki/Device_fingerprint
https://www.zdnet.com/article/firefox-to-add-tor-browser-anti-fingerpri…
Did not know that; thank!
Did not know that; thank!
> If you want to see your…
> If you want to see your own browser fingerprint, I invite you to visit AmIUnique.org.
Ad? Do you want to see the crowds of crying "I'm unique!" users again?
My FP:
"All time : But only 3 browsers out of the 1263391 observed browsers (<0.01 %) have exactly the same fingerprint as yours."
Me too (using Tails). It…
Me too (using Tails).
It seems a major reason may be that TB (in Tails at least) is *still* not properly choosing a standard size for the TB window.
Results are worse if you enable JS (slider at "safer") but bad even if you put slider to "safest".
How to interpret this? I think questions about the authors tool should be addressed in comments or in a followup.
I was surprised that in TB8…
I was surprised that in TB8 dom.storage.enabled and browser.storage.enabled are set to true?
Firefox is a leaky boat and it seems some at Mozilla are working with a drill on new versions.
We partition DOM storage so…
We partition DOM storage so that it's not usable as a tracking mechanism more across different websites. Outright disabling a feature is just the last resort but luckily we can do better in that case.
> Outright disabling a…
> Outright disabling a feature is just the last resort
Am I correct in guessing that your thinking here is that disabling a feature like DOM storage entirely would likely be noticeable by websites which could exploit this to more easily distinguish Tor Browser users from "ordinary FF"? But surely they can easily see from the IP that the visitor is coming from a Tor exit node?
Cannot Tor Project bring back Pierre Laperdrix for a followup explaining why he guesses Tor users are reporting the "almost unique" results from his fingerprinting test tool? I hope that part of the answer would be that the results reported by this tool are based almost entirely upon non-Tor users, but no-one has actually stated that, and I have found through long experience that bad things happen when no-one bothers to ask or answer questions about thoughtless assumptions which might prove to be very incorrect.
I think I support the general goal of making Tor users hard to distinguish from others (but only until almost everyone uses Tor for almost everything of course) while also making it hard to distinguish individual Tor users from other Tor users, and I can see that this hard. So we are asking questions not to criticize, only just to know.
I am not concerned about …
I am not concerned about "more easily" detecting Tor Browser users apart from Firefox users. There is probably no way to hide the former in the latter. The goal is to have a large as possible crowd of Tor Browser users being on the same Tor Browser version.
Disabling things like DOM storage harms that goal in that this breaks functionality that leads users away from Tor Browser.
Yes, Tor Browser users stand out compared to other browser users. That's already visible in the Panopticlick test which is often confusing to users. If one gets a lot of test results from browser users not using Tor Browser and mixes that up with Tor Browser user test results then it's expected that the latter stand out, which is not an issue as long as the group itself does not vary (much).
Is there some reason that…
Is there some reason that the Canvas Blocker extension is not installed by default? When it SHOULD be? It functions perfectly by default providing random hash codes for both DOMRect and canvas, leaving the user with total fingerprinting protection.
https://github.com/kkapsner/CanvasBlocker/
It's not needed and adds…
It's not needed and adds additional risk to the browser as it is additional code that is running in it which would need to get audited (basically constantly to make sure no holes are introduced with new versions). We provide a proper defense by default in Tor Browser instead.
https://www.browserleaks.com…
https://www.browserleaks.com/canvas
I've just enabled javascript for this site.
My fingerprint signature, after refreshing the page, remains static. This mean I have been positively identified by the hash code.
Can you please elaborate how I am protected against fingerprinting when I have just proven otherwise?
Thank you.
All Tor Browser users are…
All Tor Browser users are sending the same value back by default. See: https://2019.www.torproject.org/projects/torbrowser/design/ section 4.6. Cross-Origin Fingerprinting Unlinkability and there the HTML5 Canvas Image Extraction sub-section.
It might be useful to list…
It might be useful to list some of the things we might have in mind when we say that we Tor users want to appear "just like the others". Off the top of my head:
o making Tor users hard to distinguish (by studying packets from consumer device to ISP gateway) from other ISP customers who are not using Tor,
o making it hard (for that "global adversary" of ours) to tell that someone using a device which has been assigned a particular IP is using Tor at all (as I understand it, this currently seemingly impossible because we need to contact a directory authority to even join the Tor network, and we know our enemy monitors all connections to the DAs),
o making Tor packets (entry to middle node for example) hard to distinguish from other TSL bitstreams (as I understand it, there has been some progress here but the problem is not yet full solved),
o making it hard to distinguish a Tor user who is sharing a file with OnionShare from other Tor users,
o making it hard to distinguish a Tor user who is surfing to site X hard to distinguish (from src <-> entry) from one who is surfing to site Y,
o making Tor circuits being used to contact a Secure Drop hard to distinguish from "ordinary Tor circuits" (ideally from any of src <-> entry <-> middle <-> exit <-> intro <-> dst),
o making Tor users (after their traffic emerges from exit nodes) hard to distinguish from non-Tor users (currently seemingly impossible because websites can see the IP corresponds to a Tor exit node),
o making it hard to identify a Tor user even when connecting from a region with few entry nodes or with few Tor users,
o making Tor users hard to distinguish from other Tor users (after their traffic emerges from exit nodes).
(I would welcome any additions or corrections to this list.)
Some other legit goals which might sometimes be hard to reconcile with at least some of the above:
o making it easy for Tor Project (or even users?) to distinguish nodes whose operators are attempting MITM or logging traffic or otherwise doing things which resemble spookery or deeply unethical "research" on highly vulnerable humans who have not even been asked for consent from the friendly nodes,
o making it easy for friendly node operators (or Tor Project?) to learn about and correct any mis-configurations or unpatched security flaws on their node.
Regarding canvas…
Regarding canvas fingerprinting, some months ago I began to notice a weird icon appearing at many sites. Eventually someone told me this is the canvas icon and that it appears when a website is asking permission to fingerprint your browser. Reading between the lines of what you wrote, I guess FF does not ask permission, it just silently gives up the fingerprinting data, whereas TB asks the user for permission. But why on earth would a TB user say "yes"? Except by mistake? And what happens if the user fails to answer the question? After a timeout does TB assume that the user has given permission? I hope not, but I worry.
In any case, until your statement I had no reason to think TB was actually blocking the fingerprinting, although I hoped this was the case.
IMO, too often TB team makes too little effort to explain things, which causes unnecessary FUD among users (who far from being criticized for worrying about such things, should be *praised* for asking for answers). "Too little", that is, if we lived in an ideal world where Tor Project had more time to address things like user feedback. Which I admit TP mostly does not.
Still, fingerprinting seems like such a basic topic and is essential to protect against to have any chance of meeting the anonymity goals which are driving more and more ordinary people to try Tor Browser
"Ordinary people": as you no doubt know, Google Project Zero just published evidence that *all* a bad actor (said to likely be associated with a Chinese military intelligence service) attacked *all* iOS users visiting certain unnamed but "very popular" websites using sophisticated state sponsored malware. One of the targeted sites is said to be youtube.com. Apple admitted that this appears to be true, but rather horrifyingly appeared to suggest that because the presumed targets were Uyghurs, "ordinary people" need not worry. I suspect this assumption on the part of Apple is flat out wrong, and in any case I hate the suggestion that Uyghurs are not people too. Any comment?
Do you know whether Debian is addressing problems which could cause trouble for Tails as they work to release Tails 4.0.0? What about the battery API issue?
Beginning in Firefox 58, the…
Beginning in Firefox 58, the canvas icon and prompt in FF/TB controls extraction of images drawn on the canvas. The HTML5 canvas feature allows a webpage to draw or animate images. Some pages draw features on the canvas that a user may want, but extraction of those images is different. If the user fails to answer, Mike Perry said in that Firefox bug report, "In Tor Browser, we have opted to have the canvas return white image data until the user has accepted a doorhanger UI that flips a site permission to either enable or permanently block canvas access from that site."
Why are you asking Tor Project about iOS and youtube? Tor Browser doesn't even support iOS. Rather than asking Tor Project, ask individuals. Why are you asking Tor Project about Debian's effect on Tails? Ask Tails' developers about that: Support, Contact. Tails' documentation states, "Tails is a separate project made by a different group of people."
Sorry for the confusion. I…
Sorry for the confusion. I was writing quickly. Let me try again.
> "Ordinary people": as you no doubt know, Google Project Zero just published evidence that *all* a bad actor (said to likely be associated with a Chinese military intelligence service) attacked *all* iOS users visiting certain unnamed but "very popular" websites using sophisticated state sponsored malware.
Point 1: large classes of ordinary citizens not only *can* be targeted by state-sponsored malware, this is actually happening right now. Which debunks a false argument against using encryption, Tor, etc.
Point 2: large classes of ordinary citizens not only *can* be targeted by intelligence agencies which have chosen to "expend" valuable "zero-days" on unsophisticated targets, this is actually happening right now. Which debunks a false argument against using the best available defenses, such as Tails.
> One of the targeted sites is said to be youtube.com.
The revelation which shocked the security world is that everyone who visited youtube.com (and some other very popular sites) while using an iOS device may have been pwned by an intelligence agency (apparently the "E team" from the Chinese military, i.e. this was state sponsored attack using valuable zero-days, but the malware was not "A team" quality.
> Any comment?
Any further light which can be shed upon the affair is potentially valuable information to Tor users seeking to assess the dangers we face.
> Mike Perry said in that Firefox bug report, "In Tor Browser, we have opted to have the canvas return white image data until the user has accepted a doorhanger UI that flips a site permission to either enable or permanently block canvas access from that site."
Uhmm... in English?
(Not the OP, but struggling…
(Not the OP, but struggling to understand what TB does with canvas):
I take the point about not wanting to introduce more third party and possibly buggy code than needed, but do I understand what Mike Perry (as quoted elsewhere on this page) said to mean that when current TB sees a website asking for canvas data, it returns a blank white canvas image and puts up a weird little icon which is intended to warn the user that the site attempted canvas fingerprinting, and if the user clicks on the weird little icon which is intended to suggest a "canvas", the dialog they see means that TB is assuming they want to prevent that site from canvas fingerprinting the user, but they have the option to allow this if for some reason they want to allow it.
My horrible of expressing myself reflects my confusion...
While I have your attention, another issue which came up is that it is all too easy to accidently hit that tiny box which instantly maximizes the Tor Browser window--- game over. Would it be hard to simply disable that maximization box? I can see why a FF user might want to be able to maximize their browser with a click on a box, but surely not TB user would be want to do that on purpose?
That notification box will…
That notification box will be gone with Tor Browser 9.0 and letterboxing enabled.
Are you saying NoScript and…
Are you saying NoScript and the other included extensions have been/are "audited"? Scroll through the source looking for suspicious URIs and hope to find none? Or something more?
Bonjour je suis nouveau je…
Bonjour je suis nouveau je commence à connaître Tor, car j,ai vu un docu à la télé on suggère d'utiliser Protomail , Gnupg, encrypter , Jetsi.org au lieu de google utiliser DuckDuckgo ou Startpage et utilliser une antenne sur le toit pour internet gratuit .J',ai trouvé cela très intéressant comme info .Quelqu'un peut me confirmer cela et suggestion merci.
Tor Browser makes it easy …
Tor Browser makes it easy (maybe too easy) to get in the habit of searching Duckduckgo engine rather than Google search engine. If you download and install Tor Browser, in the location pane (where the url appears), try typing something which does not begin with http: or https: The browser interprets that as a search query and redirects it to Duckduckgo (by default) or to another search engine of your choosing, via tor circuits. I would advise still avoiding using Google even while using Tor Browser precisely because, as one of the papers cited in the blog post reports, Google is still by far the most determined user* of tracking technologies which unfortunately can in many cases be used to deanonymize tor users.
*In the commercial realm. NSA has not stopped piggybacking on synchronized cookies (mostly from Google or Facebook) to track individuals using tor. You may have read some months ago fake news widely reported by the mainstream media, claiming that NSA was abandoning its web and phone metadata dragnets. (Synchronized cookies are considered metadata at NSA.) In fact, a few weeks ago, NSA demanded that Congress reauthorize those programs, not just for another five years, but *indefinitely*. But mainstream media mostly ignored that inconvenient truth.
It isn't called the …
It isn't called the "location pane". It's called the address bar.
Too easy? Every major browser searches from the address bar. Pick your poison: DNS logs or search engine logs. One of the reasons why Google is so popular is because many browsers come installed configured to send all of your search queries to Google. If people are surprised to see results from a search engine that proudly asserts it doesn't track users or sell profiles, I say good. It introduces people to competitors that side more closely with users, and it introduces people to the browser's preferences so they learn how to change the search engine.
I guess I need to get out…
I guess I need to get out more :-) Almost all my recent experience is with Tails or Debian, using Tor Browser (not FF).
It is always wonderful to…
It is always wonderful to see researchers who take the time to inform users about the state of the art. Especially when the news is not bad!
Years ago I recall A. Narayan claimed (at his website) to be in the process of fingerprinting every author who ever posted anything to the web using stylometry. I wonder whether you know what the current status of that is? I hope that as with browser fingerprinting these claims have proven to be overstated.
Arvind Narayanan co-authored…
Arvind Narayanan co-authored a research paper in 2018.
I think these are not related to Narayanan, but they look fairly recent:
"The field is dominated by A.I. techniques like neural networks and statistical pattern recognition.... The content of data has a high accuracy in authorship recognition (90%+ probability)."
https://www.whonix.org/wiki/Stylometry
"Emma needs only 5,000 words to learn each unique writing style. Emma proves to be 85% accurate in attributing authorship."
http://www.aicbt.com/authorship-attribution/online-software/
"Software systems such as Signature, JGAAP, stylo and Stylene for Dutch make its use increasingly practicable, even for the non-expert."
https://en.wikipedia.org/wiki/Stylometry#Current_research
"John Olsson, however, argues that although the concept of linguistic fingerprinting is attractive to law enforcement agencies, there is so far little hard evidence to support the notion."
https://en.wikipedia.org/wiki/Forensic_linguistics#Linguistic_fingerpri…
Yes, that is who I meant. …
Yes, that is who I meant. Sorry for the goof.
Naranayan
Naranayan
The name is Narayanan, A…
The name is Narayanan, A. Narayanan.
How much anonymity can be…
How much anonymity can be expecetd with Tor Browser on the low security setting? Is it even worth using at this point, or can every PC be easily distinguished anyways?
> my Linux laptop > the user…
> my Linux laptop
> the user wants to receive her page
Are you trying to tell us something, Pierre? (:
But seriously, the extent to which everyone is lulled into giving up privacy for convenience or bureaucratic expectation is horrifying. I'm very thankful the W3C stepped in front of development to write a fingerprinting guidance document. Now we need to pressure developers to adopt it before those developers release new RFCs or proofs of concepts.
This is the first time I'm hearing about FP Central. Great news. Did you and Tor Project collaborate with ghacksuserjs who commented in June about developing TorZillaPrint?
> some elements could be rendered improperly, they could be positioned at the wrong location
Didn't Acid3 take care of this?
@TB team: It seems that the…
@TB team:
It seems that the TB team has abandoned some apparently useful things with no explanation, which I find frustrating as a user. One of these is relevant to the subject of this post:
Some time ago the TB team said TB would try to find a reasonable default size to avoid making users easily trackable because their screen size was essentially unique among Tor users owing to vagaries of the device on which they run TB.
But recently I noticed that the standard sizes seem to have been abandoned, and when I checked the amiunique website this appears to confirm that very weird nonstandard window sizes are being used to fingerprint TB users.
Any comment?
We still round the window on…
We still round the window on start-up to a multiple of 200px x 100px. Nothing has changes here. What do you get with a clean, new Tor Browser on which operating system?
Thanks for the reply. I am…
Thanks for the reply. I am using Tails 3.16 on a Dell laptop, which should act like a new clean system by intent of "amnesia" design goal, but it appears that the 200px x 100px size might be shrunk. How can I tell? The test site (from Laperdrix) showed a crazy value which would certainly be very unique.
I also use Tor Browser 8.5.latest on Debian 10 systems (laptops, PCs) but right now have no machine I would call "clean", darn it. On the least diry one it does seem that TB is choosing some kind of standard size which fits in a 1080x1920 display. The laptops use MATE and the PC uses XFCE.
@ TB team: > Maximizing Tor…
@ TB team:
> Maximizing Tor Browser can allow ...
Which begs the question: why does TB not simply disable the maximization button or at least insert a warning BEFORE the window is maximized? (The existing warning appears when the horse has already bolted from the stable, which is no help at all, agreed?)
It's hard to insert a…
It's hard to insert a warning before doing so and showing the warning and a user switching back to the standard size is not hurting much.
That said, letterboxing is supposed to fix that (we accidentally disabled it in 9.0a6 but it will be on in the next alpha again).
@ Tails team: > Figure 5:…
@ Tails team:
> Figure 5: Example of an audio fingerprint as tested on https://audiofingerprint.openwpm.com/
There is probably not much the TB team can do about onboard mikes included in almost any laptop, PC, or smart phone... but Tails can. So why are the mikes enabled by default?
(For readers who don't know, audio fingerprints are now ubiquitous for cross-platform tracking of hapless citizens.)
Go to the Tails website. …
Go to the Tails website. "Tails is a separate project made by a different group of people." Support. Contact.
From one of the papers cited…
From one of the papers cited in the post:
(Cross-)Browser Fingerprinting via OS and Hardware Level Features
Yinzhi Cao, Song Li, Erik Wijmans
> Tor Browser normalizes many browser outputs to mitigate existing browser fingerprinting. That is, many features are unavailable in Tor Browsers—based on our test, only the
following features, notably our newly proposed, still exist, which include the screen width and height ratio, and audio context information (e.g., sample rate and max channel count). We believe that it is easy for Tor Browser to normalize these remaining outputs.
>
> Another thing worth mentioning is that Tor Browser disables canvas by default, and will ask users to allow the usage of canvas. If the user does allow canvas, she can still be
fingerprinted. The Tor Browser document also mentions a unimplemented software rendering solution, however as noted in Section VI-D, the outputs of software rendering also differ significantly in the same browser. We still believe that this is the way to pursue, but more careful analysis is needed to include all the libraries of software rendering.
Does the TB team plan to make the suggested improvements to TB?
I think we did at least the…
I think we did at least the audio related ones, no?
I don't know. I was reading…
I don't know. I was reading this...
> Tor Browser normalizes many browser outputs to mitigate existing browser fingerprinting. That is, many features are unavailable in Tor Browsers—based on our test, only the following features, notably our newly proposed, still exist, which include the screen width and height ratio, and audio context information (e.g., sample rate and max channel count). We believe that it is easy for Tor Browser to normalize these remaining outputs.
... to mean that as of the date of the paper, Tor Browser has *not* normalized--- ensure that all users return the same values, I think he means--- screen width/height ratio, sample rate, max channel count.
Now I am even more confused, because I know you said above that TB *does* normalize screen width and screen height values (hence their ratio). And I am confused he says "ratio" since the pair of values is obviously more dangerous in terms of fingerprinting. My concern is that my own TB window is being "clipped" by the desktop environment (in Tails or Debian 10 as the case may be) because for some reason the window is too big for the monitor, although AFAIK my monitors are vanilla.
From a paper cited in the…
From a paper cited in the post:
Pixel Perfect: Fingerprinting Canvas in HTML5
Keaton Mowery and Hovav Shacham
> For browsers specifically designed to limit the ability of attackers to fingerprint users, such as Tor’s modified Firefox with Torbutton, more drastic steps may be necessary. Torbutton already disables WebGL, and it likely should disable GPU-based compositing and 2D canvas acceleration.
>
> But even this step does not address the fingerprint obtained through font rendering. It may be necessary for Tor’s Firefox to eschew the system font-rendering stack, and instead implement its own — based, for example, on GTK+’s Pango library.
Does the TB team plan to explore making the suggested improvements to TB?
It seems that GTK has somehow been hopelessly munged in Debian 10, which makes for example Synaptic (the package manager) very hard to use. If others confirm the issue this could cause unwanted headaches for Tails team as they prepare Tails 4.0.0 which will be based on Debian 10.
> hopelessly munged in…
> hopelessly munged in Debian 10,
The default desktop environment in Debian is Gnome, which was once a great choice but almost no-one seems to like Gnome 3. A recent article suggests that Debian users should choose instead XFCE which indeed seems to be the workable solution for PCs, if you wish to avoid pulling in privacy-hostile "features" like user-behavior-trackers and geoclue (which means Gnome and KDE are non-starters). I find that MATE works well on laptops but is unusable on a PC. Synaptic seems to have issues related to GTK3 for both XFCE and MATE. One worry going forward is that when Tails Project issues Tails 4.0 in October (this will be the first issue based upon Debian 10 "Buster"), their preferred (excellent) "Gnome classic" environment will behave badly.
From a 2015 paper cited in…
From a 2015 paper cited in the post:
The leaking battery
A privacy analysis of the HTML5 Battery Status API
Lukasz Olejnik, Gunes Acar, Claude Castelluccia, and Claudia Diaz
> As of June 2015, Firefox, Chrome and Opera are the only three browsers that supported the Battery Status API [3]. Although the potential privacy problems of the Battery Status API were discussed by Mozilla and Tor Browser developers as early as in 2012, neither the API, nor the Firefox implementation, has undergone a major revision. We hope to draw attention to this privacy issue by demonstrating the ways to abuse the API for fingerprinting and tracking.
So this has been known for long time.
It seems that most of the popular Linux distros use Battery Status API which insanely reports the battery status to double precision, which almost seems to beg for dual-purposing this "innocuous" API for tracking. Has anyone tried to ask the developers of that API what they were thinking?
Olejnik and two new coauthors revisited the issue in 2017:
Battery Status Not Included:
Assessing Privacy in Web Standards
Lukasz Olejnik, Steven Englehardt, and Arvind Narayanan
> Some implementers such as the Tor browser operate under much stricter threat models. For example, most implementers may find it acceptable to reveal the user’s operating system through a new API. But not the Tor Browser, as it attempts to maintain a uniform fingerprint across all devices.
The first paper cites the ticket https://trac.torproject.org/projects/tor/ticket/5293 which was active for 6 years, last edited 2 years ago, not clear to a user whether the problem was ever fixed or whether the TB team gave up.
The API got ripped out…
The API got ripped out browser wide, so we are good.
> Since users have different…
> Since users have different screen sizes, one way of making sure that no differences are observable is to have everyone use the same window size.
Yes, and at one time TB team appeared to try to do something like that, but more recent versions of TB seem to be happy to let FF code give the browser a unique height and width. That is bad.
Does TB team plan to address this problem?
Would it be possible to have TB report to users the current height and width so that they can to manually adjust the size to one of a small set of suggested values given for example in at www.torproject.org front page? Having TB do this automatically would be much better, though, agreed?
I am not sure what you mean…
I am not sure what you mean with "unique height and width". That's not what we reported by default unless, of course, users started to change things or the rounding we did was indeed unique among Tor Browser users.
I think letterboxing will address this problem more thoroughly, though. Watch out for the next alpha to test it. :)
Could Mozilla's letterboxing…
Could Mozilla's letterboxing technique (gray spaces) somehow allow more content to be visible compared to current Tor Browser implemention? As far as I understand both techniques this is not possible, but just want to make sure.
Also, is there any plan to apply some letterboxing techniques to zoom? I.e. when we zoom a certain page the reported window size seems to change - maybe this could be rounded to 200/100 px as well by adding gray spaces?
Letterboxing is around the…
Letterboxing is around the content window. So, you can zoom as much as you want it won't change the reported height and width.
What do you mean with the "allow more content visible" question?
So, you can zoom as much as…
Do you mean in the future Tor Browser releases or already in the current 8.5 version? When I go to https://browsersize.com/ and zoom in, the reported window size and screen size decreases (the values are at top of the page).
For example, let's say I maximize my browser's window. If I understand Mozilla's approach to letterboxing correctly, they add gray spaces around the visible page content to keep the window and screen size rounded down. I found a screenshot of this in this article: https://archive.is/XRx5N
So what those gray spaces bring to the table for Tor Browser is preventing any deanonymization via (for example) accidental maximization. But they do not increase how much of a page the user can see, i.e. even if I maximize the window, the visible page will still be contained within the same-sized rectangle while the rest of the screen will be filled with gray space. Is this correct? By the way, what happens in fullscreen mode?
I'm wondering if it's somehow possible to report rounded window/screen size values without decreasing the area of the page that the user sees. My guess is that you simply can't trick the page into thinking that area is smaller than it is.
So, for the zoom I meant in…
So, for the zoom I meant in the upcoming major release, Tor Browser 9, with letterboxing enabled. However, I looked closer now and stand corrected in that letterboxing does not solve the zoom issue automatically. We'd need to look into it.
Yes, tricking the page into thinking an area is smaller than it is is very likely futile. So the trade-off here is making the grey areas as small as possible while still providing some kind of defense against screen size fingerprinting. In fullscreen mode the same technique is applied, that is you might see gray bars around the content area.
> Browser fingerprinting has…
> Browser fingerprinting has grown a lot over the past few years. As this technique is closely tied to browser technology, its evolution is hard to predict but its usage is currently shifting.
A good example of that is fingerprinting techniques exploiting Flash. After a badly needed hue and cry from privacy advocates, including this blog site, Flash has apparently become much less used in the real world, so the bad guys (the trackers) are moving on to other classes of vulnerabilities they can exploit.
@ P. Laperdrix: A few…
@ P. Laperdrix:
A few comments on
Browser Fingerprinting: A survey
PIERRE LAPERDRIX, NATALIIA BIELOVA, BENOIT BAUDRY, and GILDAS AVOINE
I am not sure the introduction of "normalized entropy" H/(log N), where N is the size of the dataset and all logs are taken base two, is a good idea:
o log(N)-H, or better the divergence (or discrimination or cross-entropy or relative entropy or...) from uniform probability (complete anonymity), conforms with the logarithmic scale and is already very widely used in the information theory and statistics communities,
o the value of N is important and should not be suppressed.
Stating both N and the divergence is probably best.
From Table 5:
> Tor Browser
> U BA
> + : Very strong protection against fingerprinting
> − : Tor fingerprint is brittle
The endless loop: the Tor devs break a tracker, the trackers evade the breakage :-)
> The second problem with Tor browser fingerprints is their brittleness as differences can still
between browsers like the screen resolution. When first launched, the Tor Browser window has a
size of 1,000x1,000.
> However, if the user decides to maximize the window, the browser displays the following message: “Maximizing Tor Browser can allow websites to determine your monitor size, which can be used to track you. We recommend that you leave Tor Browser windows in their original default size.”. If the user has an unusual screen resolution, this information could be used to identify her as she will be the only Tor user with this screen resolution.
It's even worse than that: no sane TB user would intentionally maximize the window, but its very easy to do by mistake! And the pop-up warning only appears *after* the damage is done. (Why? why? why?)
I am not seeing TB open with a size of 1000x1000, I see it open with a size unique to the device on which I am using TB. This is a problem especially with Tails. Perhaps Tails greeter screen, or even better, Tor Browser itself, could offer a small set of sizes appropriate to a laptop, netbook, tablet, smart phone?
Thanks for writing the paper! I think it's a very useful summary.
What about sites using the mic to listen for sounds such as a passing fire engine? This kind of event (sometimes arranged by the bad guys) has been used to confirm the suspicion that a connected laptop is in a particular building. But for some reason Tails does not disable the mic by default.
Have you thought about stylometry/writeprint? Often people wish to post anonymously, for example in this very blog comment. But as Rachel or Arvind can tell you, stylometry is yet another technique which can be used to deanonymize people. IMO, too little attention has been to this. OTH, my experiments suggest that as with the fingerprinting methods you discuss, writeprints turn out to be somewhat less accurate than one's first dismal impression would suggest.
Have you thought about neuroelectrical scanners? DARPA has been working for decades on close range identification by literally sensing brainwaves, and I keep hearing that USIC is getting ready to trial such detectors at U. Maryland and such places, then in mass transit chokepoints. It is said that the goal is both to identify persons and to tell whether or not they are being truthful in their responses to TSA.
In general, there is a huge push by USG agencies (TSA HSI, DEA, FBI, CIA, Dpt of Ed, Dpt of Ag, etc) to combine multiple techniques of tracking, identification, and behavioral monitoring, and to do this on a massive scale. The techno-stasicrats envision using Big Data methods analyzed with machine learning to combine and process dragnet methods such as these:
o "remote" tracking methods of the type considered in your survey,
o phone, email, text messaging collection and analysis dragnets,
o mesh networks of faux "open access points" (used to collect WiFi device fingerprints and for real time consumer device inventories and for geolocation, with the intent of informing government officials of the "pattern of life" exhibited by each citizen, for example in hope that a sudden deviation from their individually customary daily behavior raises a "red flag"),
o mesh network connected RFID tag and bluetooth sensors,
o short range sensors (including RFID readers, bluetooth readers, WiFi device fingerprinters) installed in gateways in mass transit hubs and in the entrances to major public buildings (including privately owned buildings such as churches, as well as schools, government offices, doctors and lawyers offices),
o mesh network connected pressure sensors under roads and sidewalks,
o persistent real time "wide area" aerial surveillance, capable of tracking anything which moves (larger than a small dog) anywhere in an entire city,
o covert government audio surveillance bugs in mass transit vehicles, in streetlamps, coupled with citizen owned bugs placed "voluntarily" by homeowners in their own living rooms (Alexa, etc),
o radar, RF device, and thermal devices which can potentially monitor behavior inside the home,
o satellite and drone swarm collection of multi-spectral imagery.
Hugely redundant? Yes, that is the point. None of these dragnets by itself is 100% reliable or incapable of being evaded by a determined citizen, so governments want to implement all of them.
AFAIK, not even China has yet implemented all of these methods on a large scale, but China certainly seems to be rather openly leading the charge to do that (and *not* just in Xinjiang Province or Hong Kong). All signs indicate that such multi-tech dragnet surveillance may become ubiquitous in all countries in only a few years. Hence the need to broaden the scope of privacy-related research.
A second major trend is that in many countries, governments prefer to encourage huge corporations to construct and maintain various dragnet systems; rather than trying to do it all themselves they need only demand covert access to the vast troves of information collected by commercial trackers. Why pay for a dragnet when you can persuade companies to pay for them, and then quietly pipe the data to the spooks? This was always the danger posed by a company such as Google, and you will have observed that Google has rather openly abandoned its former promise not to share their trove of dangerous data with governments. In years past, Google and friends claimed that "Google is not going to break down your door". No, but the distinction matters little if Google hands over data which some fascist government (or private security force) uses to hunt down some minority group for the purpose of "ethnic cleansing". Such concerns appear less and less outlandish with each passing day, even in a country such as the US, whose pundits insisted for so long "that could never happen here" [sic] (ignoring the fact that it has, not once but several times in US history).
is there any way we can…
is there any way we can still modify user agent on this new tor browser? Some websites don't allow mobile devices to visit.
I was able to do it in Orfox. Please bring it back like Freddie Mercury used to say (because you don't know what it means to me.)
I like the applications
I like the applications
Okay, so i use an android…
Okay, so i use an android device. Though i am os android 7, amiunique.org says it's6.0. Okay. But i don't think my os should include android at all on Tor. Some .onion sites won't even 'talk' to an android device cuz of security concerns. Can you give me any info on this issue? It's conceivable i could tether to my desktop and hope that strips the 'android' os in favor of a win 7 environment? How does all that work?
I have visited that site and…
I have visited that site and found that my Tor browser's fingerprint differs significantly from the one mentioned in the article.
How am I expected to have exactly the same fingerprint (with the only difference, probably, is browser window site)?
When I use your https:/…
When I use your https://amiunique.org/fp in IE, there is virtuallyt no data revealed
When I use your https://amiunique.org/fp in TOR, there is a lot of data revealed
When I use your https://amiunique.org/fp in BRAVE, there is a lot of data revealed
I always thought IE was the least secure of all browsers
Can you explain this? Is IE better than TOR and BRAVE?
please have at look at what…
please have at look at what this "hacker" is doing: https://twitter.com/J0hnnyXm4s and what implications it has to this topic. Here he brags about how good they are at breaking browser privacy: https://unnamedre.com/episode/28
Here is the surveillance company he works for: https://www.kasada.io/
I think people like this are disgusting. Claiming to be protecting privacy while building a surveillance machine. It seems like they found some method to find host architecture etc by executing some code and measuring the time it takes.
Another excellent resource…
Another excellent resource that reveals what browser information is available is https://www.deviceinfo.me.
How do you tell your browser…
How do you tell your browser not to tell info about your system such as your screen size?
There is no way to be silent…
There is no way to be silent. When a page is displayed, elements on it are positioned according to the size of the browser window. The positions and size and some other attributes can be recognized by the page's code that instructed where and how to display them. One alternative to silence is to provide information that is commonplace.