Check the status of Tor services with status.torproject.org
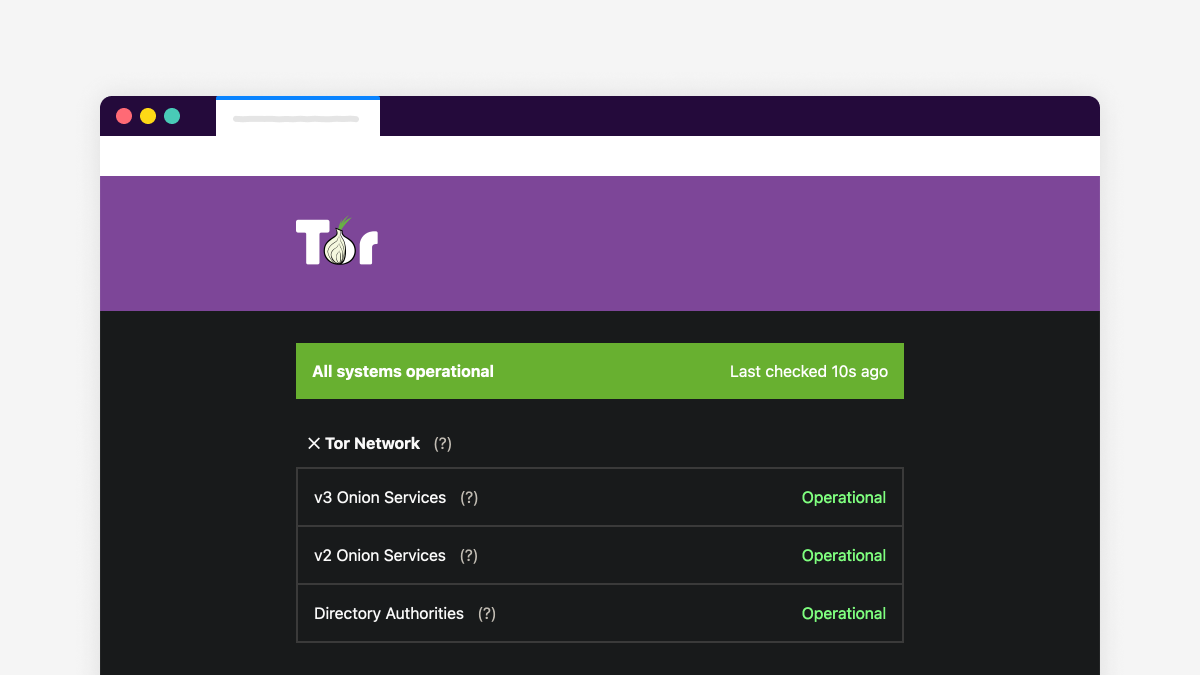
The Tor Project now has a status page which shows the state of our major services.
You can check status.torproject for news about major outages in Tor services, including v3 and v2 onion services, directory authorities, our website (torproject.org), and the check.torproject.org tool. The status page also displays outages related to Tor internal services, like our GitLab instance.
This post documents why we launched status.torproject.org, how the service was built, and how it works.
Why a status page
The first step in setting up a service page was to realize we needed one in the first place. I surveyed internal users at the end of 2020 to see what could be improved, and one of the suggestions that came up was to "document downtimes of one hour or longer" and generally improve communications around monitoring. The latter is still on the sysadmin roadmap, but a status page seemed like a good solution for the former.
We already have two monitoring tools in the sysadmin team: Icinga (a fork of Nagios) and Prometheus, with Grafana dashboards. But those are hard to understand for users. Worse, they also tend to generate false positives, and don't clearly show users which issues are critical.
In the end, a manually curated dashboard provides important usability benefits over an automated system, and all major organisations have one.
Picking the right tool
It wasn't my first foray in status page design. In another life, I had setup a status page using a tool called Cachet. That was already a great improvement over the previous solutions, which were to use first a wiki and then a blog to post updates. But Cachet is a complex Laravel app, which also requires a web browser to update. It generally requires more maintenance than what we'd like, needing silly things like a SQL database and PHP web server.
So when I found cstate, I was pretty excited. It's basically a theme for the Hugo static site generator, which means that it's a set of HTML, CSS, and a sprinkle of Javascript. And being based on Hugo means that the site is generated from a set of Markdown files and the result is just plain HTML that can be hosted on any web server on the planet.
Deployment
At first, I wanted to deploy the site through GitLab CI, but at that time we didn't have GitLab pages set up. Even though we do have GitLab pages set up now, it's not (yet) integrated with our mirroring infrastructure. So, for now, the source is hosted and built in our legacy git and Jenkins services.
It is nice to have the content hosted in a git repository: sysadmins can just edit Markdown in the git repository and push to deploy changes, no web browser required. And it's trivial to setup a local environment to preview changes:
hugo serve --baseUrl=http://localhost/ firefox https://localhost:1313/
Only the sysadmin team and gitolite administrators have access to the repository, at this stage, but that could be improved if necessary. Merge requests can also be issued on the GitLab repository and then pushed by authorized personnel later on, naturally.
Availability
One of the concerns I have is that the site is hosted inside our normal mirror infrastructure. Naturally, if an outage occurs there, the site goes down. But I figured it's a bridge we'll cross when we get there. Because it's so easy to build the site from scratch, it's actually trivial to host a copy of the site on any GitLab server, thanks to the .gitlab-ci.yml file shipped (but not currently used) in the repository. If push comes to shove, we can just publish the site elsewhere and point DNS there.
And, of course, if DNS fails us, then we're in trouble, but that's the situation anyway: we can always register a new domain name for the status page when we need to. It doesn't seem like a priority at the moment.
Comments and feedback are welcome!
Comments
Please note that the comment area below has been archived.
Clicking on torproject.org,…
Clicking on torproject.org, or Tor Check link on this status page is 404 Page not found.
That's right: components…
That's right: components which don't have documented outages have this bizarre behavior that they give a 404 instead of a more helpful message like, say, "there were no reported incidents on this component".
It seems like it's actually been fixed upstream somewhat but for some reason it still doesn't work on our end. The "affected/404" page doesn't get triggered by the ErrorDocument but anyways, it doesn't get built in the current configuration. I filed upstream issue 183 to discuss that over there.
Thanks for the report!
The onion v2 description on…
The onion v2 description on the status page could perhaps include a warning about the deprecation coming later this year. Mainly so it does not result in a lot of confusion when it goes down permanently following https://blog.torproject.org/v2-deprecation-timeline
that is a great idea! here's…
that is a great idea! here's the merge request where we're handling it. thanks for the suggestion!
Not the same person. But…
Not the same person. But have you also thought about implementing a yellow then red depreciation warning on the onion "lock logo" itself similar to HTTP security warnings? This would be the best way in my opinion to solve the fact that some people are just never going to find out themselves and suddenly lose their v2 address without redirecting users to their new v3 onion first.
Using colors to indicate…
Using colors to indicate status brings problems with localization and vision accessibility. They've been proposed many times. For example:
https://blog.torproject.org/comment/224985#comment-224985
https://blog.torproject.org/comment/281827#comment-281827
https://blog.torproject.org/comment/284093#comment-284093
https://blog.torproject.org/comment/285388#comment-285388
https://blog.torproject.org/comment/291752#comment-291752
A symbol is better, but either would have to come with an explanation or legend. Here are some recent tickets with more ideas to accelerate the transition to v3 onion services:
https://gitlab.torproject.org/tpo/applications/tor-browser/-/issues/404…
https://gitlab.torproject.org/tpo/applications/tor-browser/-/issues/404…
https://gitlab.torproject.org/tpo/applications/tor-browser/-/issues/404…
https://gitlab.torproject.org/tpo/applications/tor-browser/-/issues/404…
Thanks for promptly…
Thanks for promptly implementing a good suggestion from a user!
I surveyed internal users at…
"I outline the blog first because it's one of the most frequently used service, yet it's one of the "saddest", so it should probably be made a priority in 2021."
Thank you.
Very useful, but also a…
Very useful, but also a sobering reminder of just how centralized the tor network is :(
> how centralized the tor…
> how centralized the tor network is
Not as centralized as your comment might sound. I suggest you read:
Thank you very much for all…
Thank you very much for all the links!