Collecting, Aggregating, and Presenting Data from The Tor Network

As the makers of software dedicated to privacy and freedom online, Tor must take special precautions when collecting data to ensure the privacy of its users while ensuring the integrity of its services.
Tor Metrics is the central mechanism that the Tor Project uses to evaluate the functionality and ongoing relevance of its technologies. Tor Metrics consists of several services that work together to collect, aggregate, and present data from the Tor network and related services. We're always looking for ways to improve, and we recently completed a project, the main points of which are included in this post, to document our pipeline and identify areas that could benefit from modernization.
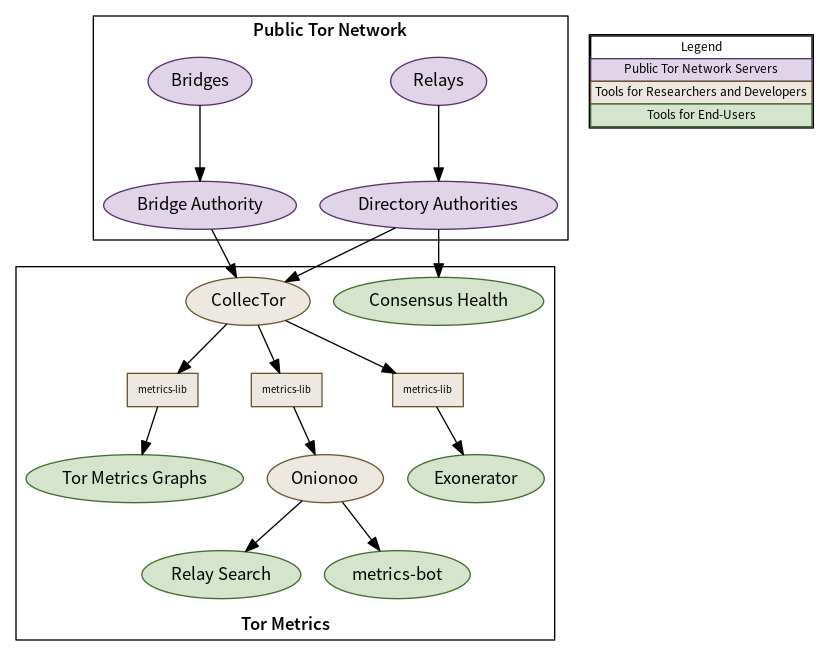
As of August 2017, all user-facing Tor Metrics content has moved (back) to the Tor Metrics website. The main reason for gathering everything related to Tor Metrics on a single website is usability. In the background, however, there are several services distributed over a dozen hosts that together collect, aggregate, and present the data on the Tor Metrics website. Almost all Tor Metrics codebases are written using Java, although there is also R, SQL and Python. In the future we expect to see more Python code, although Java is still popular with academics and data scientists and we would like to continue supporting easy access to our data for those that want to use Java even if we are using it less ourselves.
Tor relays and bridges collect aggregated statistics about their usage including bandwidth and connecting clients per country. Source aggregation is used to protect the privacy of connecting users—discarding IP addresses and only reporting country information from a local database mapping IP address ranges to countries. These statistics are sent periodically to the directory authorities. CollecTor downloads the latest server descriptors, extra info descriptors containing the aggregated statistics, and consensus documents from the directory authorities and archives them. This archive is public and the metrics-lib Java library can be used to parse the contents of the archive to perform analysis of the data.
In order to provide easy access to visualizations of the historical data archived, the Tor Metrics website contains a number of customizable plots to show user, traffic, relay, bridge, and application download statistics over a requested time period and filtered to a particular country. In order to provide easy access to current information about the public Tor network, Onionoo implements a protocol to serve JSON documents over HTTP that can be consumed by applications that would like to display information about relays along with historical bandwidth, uptime, and consensus weight information.
An example of one such application is Relay Search which is used by relay operators, those monitoring the health of the network, and developers of software using the Tor network. Another example of such an application is metrics-bot which posts regular snapshots to Twitter and Mastodon including country statistics and a world map plotting known relays. The majority of our services use metrics-lib to parse the descriptors that have been collected by CollecTor as their source of raw data about the public Tor network.
As the volume of the data we are collecting scales over time, with both the growth of the Tor network and an increase in the number of services providing telemetry and ecosystem health metrics, some of our services become slow or begin to fail as they are no longer fit for purpose. The most critical part of the Tor Metrics pipeline, and the part that has to handle the most data, is CollecTor. In charge of collecting and archiving raw data from the Tor ecosystem, an outage or failure may mean lost data that we can never collect. For this reason we chose CollecTor as the service that we would examine in detail and explore options for modernization using technologies that had not been available previously.
The CollecTor service provides network data collected since 2004, and has existed in its current form as a Java application since 2010. Over time new modules have been added to collect new data and other modules have been retired as the services they downloaded data from no longer exist. As the CollecTor codebase has grown, technical debt has emerged as we have added new features without refactoring existing code. This results in it becoming increasingly difficult to add new data sources to CollecTor as the complexity of the application increases. Some of the requirements of CollecTor, such as concurrency or scheduling, are common to many applications and frameworks exist implementing best practices for these components that could be used in place of the current bespoke implementations.
During the process of examining CollecTor's operation, we discovered some bugs in the Tor directory protocol specification and created fixes for them:
• The extra-info-digest's sha256-digest isn't actually over the same data as the sha1-digest (#28415)
• The ns consensus isn't explicitly ns in the network-status-version line of flavored consensuses (#28416)
During the process we also requested some additional functionality from stem that would allow for a Python implementation, which was implemented to support our prototype:
• Parsing descriptors from a byte-array (#28450)
• Parsing of detached signatures (#28495)
• Generating digests for extra-info descriptors, votes, consensuses and microdescriptors (#28398)
A prototype of a "modern CollecTor" was implemented as part of this project. This prototype is known as bushel and the source code and documentation can be found on GitHub at https://github.com/irl/bushel. In the future, we hope to build on this work to produce an improved and modernized data pipeline that can better both help our engineering efforts and assist rapid response to attacks or censorship.
For the full details from this project, you can refer to the two technical reports:
Iain R. Learmonth and Karsten Loesing. Towards modernising data collection and archive for the Tor network. Technical Report 2018-12-001, The Tor Project, December 2018.
Iain R. Learmonth and Karsten Loesing. Tor metrics data collection, aggregation, and presentation. Technical Report 2019-03-001, The Tor Project, March 2019.
Comments
Please note that the comment area below has been archived.
Tor is apparently blocking…
Tor is apparently blocking me from using my debit card online. Is there a fix?
E-commerce sites and your…
E-commerce sites and your card provider may use "IP reputation databases" to determine when a transaction is at higher risk of being fraudulent. Studies have shown that the number of fraudulent transactions on Tor vs. legitimate ones is roughly the same as for the public Internet, however on the public Internet the transactions will be spread out over millions of IP addresses.
If you see a fraudulent transaction coming from an IP address on the public Internet, you might restrict that IP address from making further transactions in case they are fraudulent too. When you use Tor, you're using a very small pool of IP addresses (those belonging to exit relays). You have millions of users sharing thousands of addresses and the server cannot tell users apart. IP reputation databases weren't designed for this, and so even the low level of fraudulent transactions that occur over Tor (in roughly the same proportion as the public Internet) can cause an IP address to be blocked from performing transactions.
I have personally found that I'm able to conduct online banking via Tor without issues, and even made card payments occasionally without issues. You could try another card provider but in the end it is really up to the e-commerce site or payment processor how they detect fraud.
Our latest statistics on the number of daily users can be found at:
https://metrics.torproject.org/userstats-relay-country.html
Our latest statistics on the number of exit relays can be found at:
https://metrics.torproject.org/relayflags.html
The last count is 1952545 users to 845 exit relays, or roughly 2310 users per exit relay.
Thanks to the metrics team…
Thanks to the metrics team for your work! The graphic is very helpful.
The OT thread above is of independent interest and I wish TP had a procedure to encourage more such back and forth on issues encountered by Tor users, which are often not addressed by any documentation easily accessible to the average user. One possibility would be to start a tradition inspired by Schneier's weekly cat posts in which he encourages readers to ask him anything in the comments; TP could post weekly pictures of the mascot and encourage readers to ask questions they could not get answered elsewhere.
I wasn't aware of those…
I wasn't aware of those posts, but it sounds like an interesting approach, I will certainly pass the idea along.
Also on social media, but…
Also on social media, but the blog here is convenient in that it doesn't need registration. We'd like to post on Safest though.
Popular AMA questions can be incorporated into the FAQ afterwards. We'd like to be able to search it by then.
I discussed this with some…
I discussed this with some Tor people yesterday, and it is something we're thinking about doing.
As for the FAQ, we do have the support portal at https://support.torproject.org/ and it seems that the question in the above thread was answered there although differently.
Housekeeping. Good. Thank…
Housekeeping. Good. Thank you. 2010? Wow.
Please be sure to care for their onion domains too. Is a transition to V3 domains in the pipeline?
What do the colors of the circles on metrics-bot's maps mean?
Why not serve bushel's code on gitweb.torproject.org with the other Tor Projects? Why GitHub, especially now that Microsoft owns it?
As I understand it, we…
As I understand it, we cannot yet transition to v3 onion services due to the lack of OnionBalance support. You can track the progress for that support in our bug tracker.
https://bugs.torproject.org/26768
With metrics-bot:
* green means Exit
* blue means Guard
* orange means Authority (might be hard to spot this)
* yellow means anything that wasn't an Exit, Guard or Authority
bushel was only a prototype. I have continued to work on it in my free time, but right now I'm the only person working on it as this project has come to an end. The "canonical" repository is the one on my workstation, but if bushel does remain relevant then I will move it to git.torproject.org with a GitHub mirror. GitHub also provides integration with Travis CI which I've been using for testing.
Time and time again data…
Time and time again data collection always goes bad !!
Indeed! This is why we put…
Indeed! This is why we put so much effort into making sure our collection of data is safe.
Our original efforts were published in a peer-reviewed paper. This allowed us to have academics look over the methodologies and point out areas for improvement.
We established a series of principles that ensure that the data collection is safe. These include data minimalisation, source aggregation and transparency of methodologies.
The collection of data helps to improve the safety of the Tor network, by detecting possible censorship events or attacks against the network.
More recently, I have been looking at standardising our safety principles through the Internet Research Task Force to produce an RFC applicable to the wider Internet. You can read a draft text here:
https://datatracker.ietf.org/doc/draft-learmonth-pearg-safe-internet-me…
I just want to say that it's…
I just want to say that it's so great that you guys reply to the comments in here.
Thanks! It's great that…
Thanks! It's great that people had such good questions too.