Cooking with Onions: Finding the Onionbalance

Hello,
This blog post is the first part of the Cooking with Onions series which aims to highlight various interesting developments on the .onion space. This particular post presents a technique for efficiently scaling busy onion services.
The need for scaling
Onion services have been around for a while. During the past few years, they have been deployed by many serious websites like major media organizations (like the Washington Post), search engines (such as DuckDuckGo) and critical Internet infrastructure (e.g. PGP keyservers). This has been a great opportunity for us, the development team, since our code has been hardened and tested by the sheer volume of clients that use it every day.
This recent widespread usage also gave us greater insights on the various scalability issues that onion service operators face when they try to take their service to the next level. More users means more load to the onion service, and there is only so much that a single machine can handle. The scalability of the onion service protocol has been a topic of interest to us for a while, and recently we've made advancements in this area by releasing a tool called Onionbalance.
So what is Onionbalance?
Onionbalance is software designed and written by Donncha O'Cearbhaill as part of Tor's Summer of Privacy 2015. It allows onion service operators to achieve the property of high availability by allowing multiple machines to handle requests for a single onion service. You can think of it as the onion service equivalent of load balancing using round-robin DNS.
Onionbalance has recently started seeing more and more usage by onion service operators! For example, the Debian project recently started providing onion services for its entire infrastructure, and the whole project is kept in line by Onionbalance.
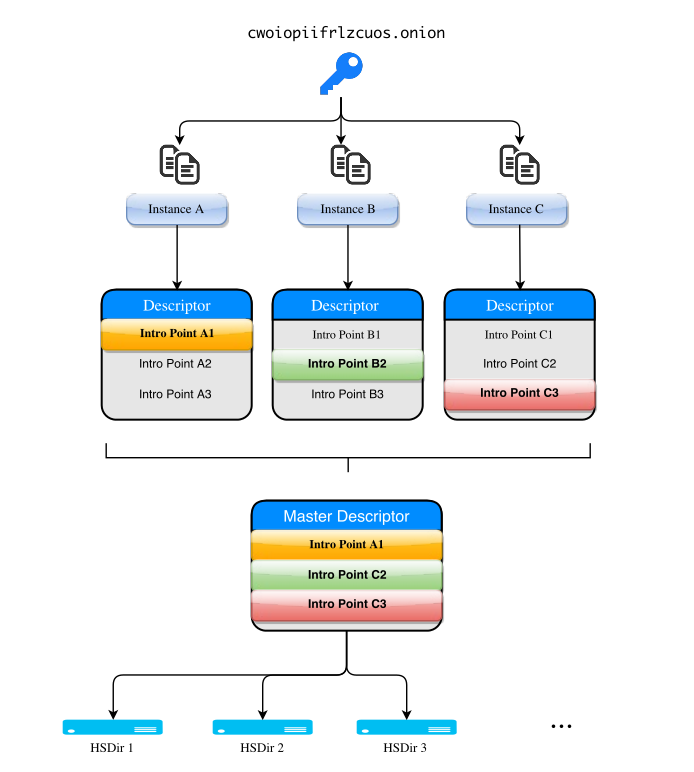
How Onionbalance works
Consider Alice, an onion operator, who wants to load balance her overloaded onion service using Onionbalance.
She starts by setting up multiple identical instances of that onion service in multiple machines, makes a list of their onion addresses, and passes the list to Onionbalance. Onionbalance then fetches their descriptors, extracts their introduction points, and publishes a "super-descriptor" containing all their introduction points. Alice now passes to her users the onion address that corresponds to the "super-descriptor". Multiple Onionbalance instances can be run with the same configuration to provide redundancy when publishing the super descriptor.
When Bob, a client, wants to visit Alice's onion service, his Tor client will pick a random introduction point out of the super-descriptor and use it to connect to the onion service. That introduction point can correspond to any of the onion service instances, and this way the client load gets spread out.
With Onionbalance, the "super-descriptor" can be published from a different machine to the one serving the onion service content. Your onion service private key can be kept in a more isolated location, reducing the risk of key compromise.
For information on how to set up Onionbalance, please see the following article:
http://onionbalance.readthedocs.io/en/latest/
Conclusion
Onionbalance is a handy tool that allows operators to spread the load of their onion service to multiple machines. It's easy to set up and configure and more people should give it a try.
In the meanwhile, we'll keep ourselves busy coming up with other ways to scale onion services in this brave new world of onions that is coming!
Take care until the next episode :)
Comments
Please note that the comment area below has been archived.
tor is dead...
tor is dead...
Millions of users beg to
Millions of users beg to differ, and the only thing that is dead is democratic ideals based on the actions of three letter agencies gone wild.
We should welcome a battle-scarred Tor network and browser being attacked constantly by the Feds, as it just pushes developments further e.g. onion balancing, increased scaling of the onion network, greater adoption by websites of .onions that solve the CA debacle, quantum computer-resistant cypher development, (eventual) padding of Tor traffic and more.
Tor and Tor browser are not going anywhere, and potential competitors run a distant second in terms of user population and actual functionality.
If the retards running major internet infrastructure and websites actually invested heavily in the Tor network and shifted operations to .onions, the Tor network can be the blueprint for the new and vastly improved internet that is required, because the http/https model right now is f**ked security-wise.
To extend your response to
To extend your response to the OP:
Let us not forget that most if not all of the LE hacks we know about have been compromises on endpoint security (compromising the server at the application level, exploiting browsers and distributing a malicious payloads, or often both), and not at the transport layer. The biggest compromise of the Tor protocol I can think of off the top of my head was the CMU hack that abused the RELAY_EARLY flag. That one was serious indeed, and did result in some arrests, but these kinds of attacks seem relatively rare so far.
> Tor and Tor browser are
> Tor and Tor browser are not going anywhere,
I believe that increasing pressure will be placed on relay operators. They will become more liable for the traffic they carry. It may even become a crime to knowingly help others to remain anonymous.
I already carry a biometrically verified identification card with a number to use in online transactions. I believe it is planned that that number will be used as a login to access the Internet from within my country.
Unique, trackable, and revocable licenses that are necessary to get online are coming.
Tor is dead good. There,
Tor is dead good.
There, fixed that for you.
Interestingly enough, some
Interestingly enough, some of the deleted comments quoted from GCHQ troll manuals leaked by Snowden, which show that short repetitive FUD comments which offer no support for their claims that "resistance is useless" [sic], are standard practice by GCHQ comment trolls.
Other deleted comments explored the habits of RU and CN funded comment trolls.
Some days it seems that the only point on which FVEY, RU, CN agree is that they insist on doing all the thinking for their own citizens, they reject any attempt by "the rabble" to try to define themselves, and especially any attempt to express dissent in an effective manner which might actually reduce the power and influence of the socioeconomic-poltical elite.
Yeah, I note there is a kind
Yeah, I note there is a kind of Murphy's law (I can't find its name) along the lines of "The effort to undo damage is greater than the effort taken to cause it." It can takes ages to repair the damage caused by very short acts of shitposting. Here, I just saw a very quick way to reverse the intent of the original shitpost. Not rational, but effective. Shame a long comment interposed itself, mitigating the impact ...
I suspect that one was from @movrcx himself; his tweets were saying similar things at the time.
On the other hand, if it is NSA/TAO operators, what a doss of a job! Maybe I'm missing my vocation: what's the pay like? Where do I apply!?
Ever heard about "persona
Ever heard about "persona management" ? NSA seems to have a lot of fun with it's budget.
"Tor is dead", you
"Tor is dead", you say?
Snowden doesn't think so, in fact only a few days ago he retweeted some good advice:
> Edward Snowden @Snowden Sep 21
> Edward Snowden Retweeted Al96
> Use Tor. Use Signal.
Thanks, but 40 bits of
Thanks, but 40 bits of entropy is not enough to verify the public key of the Onion server.
This absolutely needs work!
Hmm, what do you mean
Hmm, what do you mean exactly? Where did you get the 40bits value?
FWIW, onion addresses are 80-bit truncated hashes.
The output of SHA1 has a
The output of SHA1 has a length of 160 bit. To make handling the URLs more convenient we only use the first half of the hash, so 80 bit remain. Taking advantage of the Birthday Attack, entropy can be reduced to 40 bit.
See https://trac.torproject.org/projects/tor/ticket/18191
I think the birthday attack
I think the birthday attack you described above only applies when you are trying to generate two arbitrary onion addresses that collide. That's not that strong of an attack, because it does not allow you to impersonate specific onion services.
Now, if you are trying to create a collision to a _specific_ onion address (targetted), the birthday attack argument does not work.
Could you please expand on
Could you please expand on this?
For the consensus to reject such a colliding (40-bits) hash, I assume the entire (80-bits) key hash (or the entire key itself?) is remembered by the directories on the "first claimed, first assigned" basis.
If they were remembered forever, then the entire onion directory would be pretty vulnerable to malicious overload. Right? So how long are the claims remembered?
Looking at Tor design documents, I failed to figure what would be an onion TTL (Time To Live) in the consensus. I only found about the requirement for the onion operator to keep publishing on a regular interval (recommended at least every 20 hours, if I remember correctly).
Does it also imply that, whenever failing to do so, the "40-bit hash lease" of the onion would end up being forgotten and as such could be obtained again (malicously or not doesn't really matter here), by such a colliding (40-bit) hash key, and as fast as a couple of days after the original publisher would cease to do so?
(Moderator: please drop my
(Moderator: please drop my queued comment 213941, I understand it was erroneous. Thanks)
For the time being (until the said "proposal 224" gets implemented), all I found in Tor design docs about what would be an "onion TTL", is as follow:
The directory server remembers this descriptor for at least 24 hours after its timestamp. At least every 18 hours, Bob's OP uploads a fresh descriptor
https://gitweb.torproject.org/torspec.git/tree/rend-spec.txt#n490
If the OP fails to do so in time, I understand the onion's public key could entirely disappear from the consensus as soon as 6 hours after the deadline. And therefore, the (80-bit) onion address could theorically be "granted" again to an entirely different public key with a colliding onion address, from that moment and as long as the new one would keep being published.
I understand such a collision is considered "unlikely" (malicious or not) due to the 80-bit entropy. Still, is this correct?
Do directories already implement any mechanism to detect, remember and publish a colliding address (at least to clients querying one)? Has any one ever been detected, or reported manually, to date?
Onion address: 16 chars in
Onion address: 16 chars in base 32: 16 × 5 bits = 80 bits.
PGP key fingerprint: 40 digits in hex: 40 × 4 bits = 160 bits.
OK, 80 bits not 40 bits, so I think the OP miscalculated, but if we take his point, then aren't there plans for 56 char base 32 next gen onion addresses? That's 280 bits, right?
As explained above, the
As explained above, the Birthday Attack reduces the number of bits of entropy to 40 bits
Ah, I see, though that
Ah, I see, though that wasn't stated in the original post.
Can we be happy that next generation onion addresses with about 56 base 32 characters will give about 140 bits of entropy? Is that enough?
What's the onion address of
What's the onion address of The Washington Post?
Hey guy, take a look here
Hey guy, take a look here first:
https://www.washingtonpost.com/securedrop/
Then try the below address of hidden service!
vbmwh445kf3fs2v4.onion
I'm not your guy, friend
I'm not your guy, friend
I am no expert, but I am
I am no expert, but I am starting to hope that if scaling issues can be miraculously solved without compromising security, onion services could perhaps solve the horrid problems with CAs (cf the grotesque abuses which the spooks chortle about at ISS World conferences).
Please keep working to improve Tor!
Nice!!! Thanks a
Nice!!! Thanks a lot!
*installing*
Using Tor to make online
Using Tor to make online purchases causes accounts to be frozen due to malicious activity? HELP?!
Making (standard) online
Making (standard) online purchases requires identifying information, for that matter you can't use it via the Tor network. Your best bet is to look at crypto-currencies such as Bitcoins, which would allow for such (standard) online purchases if supported.
Alas, Tor Project cannot do
Alas, Tor Project cannot do much to alter the tendency of many website maintainers to reflexively ban all Tor nodes, or to otherwise discourage their customers from using Tor. In some countries, websites may also be struggling to obey government mandates to block Tor.
You were probably talking about electronic currency payments, but if you are are trying to send credit card information over an unencrypted connection (from exit node to the destination website), that could be dangerous.
EPIC PRIVACY BROWSER WORKS
EPIC PRIVACY BROWSER WORKS FINE TOO THAN TOR?
Is the "Master Descriptor"
Is the "Master Descriptor" in the image the same as the
"super-descriptor" of the text description?
I think in the image the green colored second intro point
of the master descriptor should read "B2" instead of "C2".
I really hope this
I really hope this ameliorates both the scalability as well as the security of onion services. Keep up the great work!
It looks like a sabotage.
It looks like a sabotage. Onion services are only needed if both users and servers need anonymity. The ones who use lots of 1-hop onions are easy to anonymize. And anonymizing services reduces anonymity of users. Why don't you make Tor to mark such servers as less secure and why don't you discourage their use? If you are not about anonymity, and privacy, then please stop claim so.
Easy to... *de*anonymize?
Easy to... *de*anonymize?
Why do you let the tor
Why do you let the tor client pick the onion introduction point? Someone trying to overload a onion service will have all their coordinated DDoSing tor clients pick the same intro point, no?
The new onion site mirrors
The new onion site mirrors for Debian stable "main" repos use OnionBalance, and the onion sites are now working better for me than the unprotected mirrors.
So thanks, and more like this please!
Can tails.boum.org set up an
Can tails.boum.org set up an onion site mirror? If they use OnionBalance this could perhaps help users who need to obtain the full iso image for the latest Tails.