Some statistics about onions

Non-technical abstract:
We are starting a project to study and quantify hidden services traffic. As part of this project, we are collecting data from just a few volunteer relays which only allow us to see a small portion of hidden service activity (between 2% and 5%). Extrapolating from such a small sample is difficult, and our data are preliminary.
We've been working on methods to improve our calculations, but with our current methodology, we estimate that about 30,000 hidden services announce themselves to the Tor network every day, using about 5 terabytes of data daily. We also found that hidden service traffic is about 3.4% of total Tor traffic, which means that, at least according to our early calculations, 96.6% of Tor traffic is *not* hidden services. We invite people to join us in working to research methodologies and develop systems for better understanding Tor hidden services.
Hello,
Over the past months we've been working on hidden service statistics. Our goal has been to answer the following questions:
- "Approximately how many hidden services are there?"
- "Approximately how much traffic of the Tor network is going to hidden services?"
We chose the above two questions because even though we want to understand hidden services, we really don't want to harm the privacy of Tor users. From a privacy perspective, the above two questions are relatively easy questions to answer because we don't need data from clients or the hidden services themselves; we just need data from hidden service directories and rendezvous points. Furthermore, the measurements reported by each relay cannot be linked back to specific hidden services or their clients.
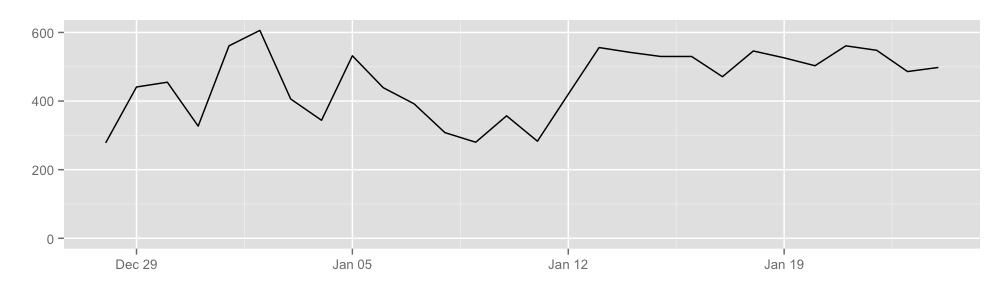
Our first move was to research various ways we could collect these statistics in a privacy-preserving manner. After days of discussions on obfuscating statistics, we began writing a Tor proposal with our design, as well as code that implements the proposal. The code has since been reviewed and merged to Tor! The statistics are currently disabled by default so we asked volunteer relay operators to explicitly turn them on. Currently there are about 70 relays publishing measurements to us every 24 hours:
So as of now we've been receiving these measurements for over a month, and we have thought a lot about how to best use the reported measurements to derive interesting results. We finally have some preliminary results we would like to share with you:
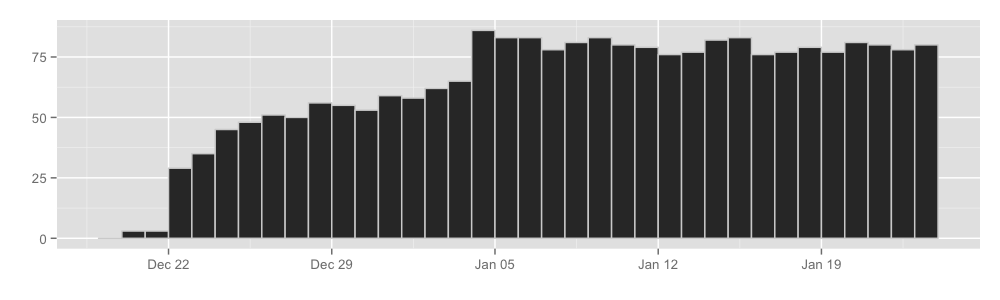
How many hidden services are there?
All in all, it seems that every day about 30000 hidden services announce themselves to the hidden service directories. Graphically:
By counting the number of unique hidden service addresses seen by HSDirs, we can get the approximate number of hidden services. Keep in mind that we can only see between 2% and 5% of the total HSDir space, so the extrapolation is, naturally, messy.
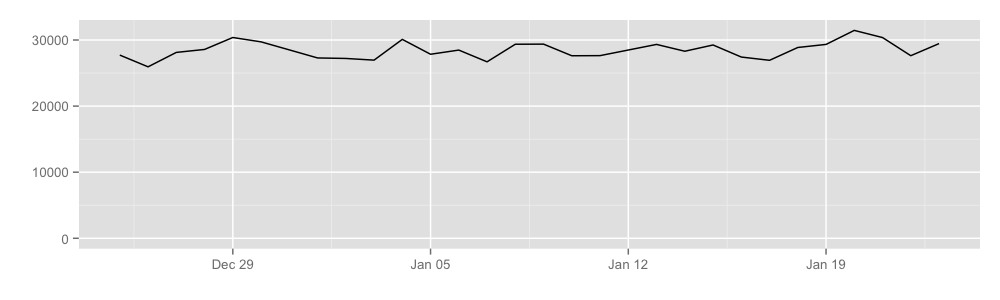
How much traffic do hidden services cause?
Our preliminary results show that hidden services cause somewhere between 400 to 600 Mbit of traffic per second, or equivalently about 4.9 terabytes a day. Here is a graph:
We learned this by getting rendezvous points to publish the total number of cells transferred over rendezvous circuits, which allows us to learn the approximate volume of hidden service traffic. Notice that our coverage here is not very good either, with a probability of about 5% that a hidden service circuit will use a relay that reports these statistics as a rendezvous point.
A related statistic here is "How much of the Tor network is actually hidden service usage?". There are two different ways to answer this question, depending on whether we want to understand what clients are doing or what the network is doing. The fraction of hidden-service traffic at Tor clients differs from the fraction at Tor relays because connections to hidden services use 6-hop circuits while connections to the regular Internet use 3-hop circuits. As a result, the fraction of hidden-service traffic entering or leaving Tor is about half of the fraction of hidden-service traffic inside of Tor. Our conclusion is that about 3.4% of client traffic is hidden-service traffic, and 6.1% of traffic seen at a relay is hidden-service traffic.
Conclusion and future work
In this blog post we presented some preliminary results that could be extracted from these new hidden service statistics. We hope that this data can help us better gauge the future development and maturity of the onion space as well as detect potential incidents and bugs on the network. To better present our results and methods, we wrote a short technical report that outlines the exact process we followed. We invite you to read it if you are curious about the methodology or the results.
Finally, this project is only a few months old, and there are various plans for the future. For example:
-
There are more interesting questions that we could examine in this area. For example: "How many people are using hidden services every day?" and "How many times does someone try to visit a hidden service that does not exist anymore?."
Unfortunately, some of these questions are not easy to answer with the current statistics reporting infrastructure, mainly because collecting them in this way could reveal information about specific hidden services but also because the results of the current system contain too much obfuscating data (each reporting relay randomizes its numbers a little bit before publishing them, so we can learn about totals but not about specific events).
For this reason, we've been analyzing various statistics aggregation protocols that could be used in place of the current system, allowing us to safely collect other kinds of statistics.
- We need to incorporate these statistics in our Metrics portal so that they are updated regularly and so that everyone can follow them.
-
Currently, these hidden service statistics are not collected in relays by default. Unfortunately, that gives us very small coverage of the network, which in turn makes our extrapolations very noisy. The main reason that these statistics are disabled by default is that similar statistics are also disabled (e.g. CellStatistics). Also, this allows us more time to consider privacy consequences. As we analyze more of these statistics and think more about statistics privacy, we should decide whether to turn these statistics on by default.
It's worth repeating that the current results are preliminary and should be digested with a grain of salt. We invite statistically-inclined people to review our code, methods, and results. If you are a researcher interested in digging into the measurements themselves, you can find them in the extra-info descriptors of Tor relays.
Over the next months, we will also be thinking more about these problems to figure out proper ways to analyze and safely measure private ecosystems like the onion space.
Till then, take care, and enjoy Tor!
Comments
Please note that the comment area below has been archived.
Unfortunately is the
Unfortunately is the procedure at https://www.torproject.org/docs/debian in order to help you as a volunteer is not working:
After the command "gpg --keyserver keys.gnupg.net --recv 886DDD89", here is what i have:
fix it please
Look at the error messages
Look at the error messages carefully, "keys.gnupg.net: Host not found" sounds like a network problem on your end.
I've a better idea for you
I've a better idea for you to work on.
In addition to just collecting statistics, could you invite some black-hat hackers to hack the Tor network to see how resilient it is against attacks?
Or, you could employ a few experts to conduct a security audit of the products developed by Tor?
Wow, they probably never
Wow, they probably never thought about that. /s
LOL! Well, someone call the
LOL! Well, someone call the hackers asap!!!
Of course, I'm using a Mac so it's not like I have anything to worry about. Macs are invincible!
TORPROJECT won the reddit
TORPROJECT won the reddit donation of nearly $83K. Make sure the founders/developers work out the details with reddit team via redditdonate@reddit.com.
My Friends in iran says :all
My Friends in iran says :all Anti-Filter softwares , VPN's (Open vpn ,PPTP,L2TP) are down .and also Tor does Not work in some area . The Government has been blocked some Bridges . i saw the Tor Metrics .it seems Tor users From Iran have been Increased...
Please Put New bridges !
i'm from iran with Tails and
i'm from iran with Tails and obfs3 bridge :) . and i don't have any issue . use obfs3 bridge https://bridges.torproject.org/ . some bridges are very slow and you should get more than 3 bridge from above links . good luck
Tails 1.3 includes the
Tails 1.3 includes the pluggable transport obfs4. You might give obfs4 a try if nothing else works.
I am an iranian atheist. I'm
I am an iranian atheist.
I'm a blogger.
the tor is helpful for me.
your efforts for freedom is admirable.
thanks.
there is no way we can
there is no way we can connect to tor in Iran anymore its more than 10 days that even bridges don't do there job here, by the way tor bundle surprisingly still works.
how would you set up your
how would you set up your own hidden service? using TBB is easy, but what webservers or http libraries can be relied on not to disclose your identity? its a curious gap in the ease of use of tor that you have to figure that out for yourself and might make a mistake
I've used Boa, OpenBSD's
I've used Boa, OpenBSD's httpd, Nginx, and Apache.
Boa
Boa is a good webserver for super simple entirely static web pages (it only supports serving static files, no CGI etc). It is /extremely/ small and very fast. The small code size also means it has very few vulnerabilities, especially very few information leaks. If you have absolutely 0 experience with web servers, Boa will still be very easy to use. I highly recommend it if you only want to serve static content (static content isn't just HTML, you can also serve HTML5, CSS, JavaScript, etc. Just no server-side languages like PHP).
lighthttpd
I have heard good things about lighthttpd (it should be able to do most of what you would want to put on a website), because it's small, secure, and fast. That's only an anecdotal recommendation though, I haven't played with lighthttpd myself.
OpenBSD's httpd
If you are using OpenBSD, their httpd is a step up from Boa in features It's fairly immature, with only basic CGI and FastCGI support, primitive TLS support, and a very simple config file, but it should be more complete in the future. The OpenBSD team has a reputation for very thorough code auditing, so their code is exceptionally high quality. If the famous OpenSSH is anything to go by, their httpd should be quite solid as well.
Nginx
And of course the overall best if you need advanced features or high quality documentation is Nginx (the main competitor to the terrible Apache webserver). If you want to minimize information leakage (e.g. the daemon being tricked into giving up info like your hostname or more), then go with something ultra simple like Boa or OpenBSD's httpd. If you need more advanced features, stick with Nginx but read up on how to make it secure (specifically secure against information leaks).
Apache
Do not use Apache. It is more vulnerable to denial of service attacks (especially because it spawns an entire new worker process for /every/ new TCP connection), as well as information disclosure and remote code execution exploits.
All of those web servers can be easily pointed at the localhost address your hidden service forwards to. I suggest you have the HS port be port 80, both externally and on localhost, to avoid some annoying bugs that many webservers can cause when the external port != the port the daemon listens to.
tl;dr use Boa if you are only serving static content, use Nginx otherwise. If you are using OpenBSD or want to try it, use their custom httpd.
Anyway you must communicate
Anyway you must communicate onion address of your site so you can use any port not only 80. "well known port" != "port must be used".
If you are going to have public web server try to restrict information about used software and os. Though it is true that tor prevents ip/tcp level fingerprinting, your web server can happily announce that it is windows 98 it is running on.
If it is a private web you can use an old microsoft trick - ask users to set useragent like "It's me JackTheRipper" and filter requests accordingly. I believe palemoon browser has an option to set customized ua strings for distinct sites.
I believe I heard Roger
I believe I heard Roger Dingledine say something about spinning up instances in Twisted becoming the norm for onion web services. I would like to learn more.
I'm a bit surprised that
I'm a bit surprised that nobody has made a comment about the actual point of the article. Hey, guys, aren't you at all interested in knowing what happens in the tor space ? I mean, I find this study, despite the small means they had, and the statistical irregularities that appear (due to the small amount of data, not to the work of the researchers), quite interesting. I used Tor during a long time, some years ago, and when I came back, my first question was : is there really something left in the hidden part, or is it now just a playground for teenagers looking for some adrenaline and scams of drugs-selling or weapons-selling websites ?
And this is a good way to answer this question, without, so far, attacking anyone's privacy.
I may have some skills about statistical studies, and I'd be happy to put them in good use. If someone is ready to discuss, on a technical and theoretical point of view, the pertinency of this study, and interprate, as much as it is possible, its results, I'd be glad to have a talk about it.
Well it's not just "scams of
Well it's not just "scams of drugs-selling or weapons-selling websites" but serious agencies collecting reports from agents by the way...
As for statistics are you really sure it should be interesting for tor users? How can this research be used for increasing security of tor network? And as you can see the researchers themselves are afraid of using tor HS for presenting their results! btw there can be possible outcome of such statistics as for example a signal for a new raid on hs operators! Researchers are mad on their researches and usually absolutely don't care and can't predict outcome of their researches.
And of course some relay operators always use patched tor code for different purposes. I'm sure in the researchers' case the operators review such patches.
As i see it is more interesting how the network can prevent attempts to analyze its behavior, detect modified nodes and mark them as potentially unsafe (say - experimental) in consensus for allowing users to avoid such relays.
I would like to see the
I would like to see the numbers going to known CP sites and maybe some way to try block them or even just let their info leak so they get arrested and have their ass well pounded in prison.
Another option is to let me know any pedo's and I'll gladly end those kids suffering by seeing what these guys do when confronted by a man who is most likely bigger and stronger than them(6'4" active Muay Thai boxer), its usually guys but I'd have a different approach to women, I'd make them see how the kids feel, you know what? Just for the kids they abused I'd put myself threw raping a guy, sure I'd not like it in the slightest but this isn't about me, its these kids that have their innocence taken at very young age, I can tell you from experience it is a life altering experience for most and some are as young as 3, 4, 5 years of age.