Improving Tor's anonymity by changing guard parameters

There are tensions in the Tor protocol design between the anonymity provided by entry guards and the performance improvements from better load balancing. This blog post walks through the research questions I raised in 2011, then summarizes answers from three recent papers written by researchers in the Tor community, and finishes by explaining what Tor design changes we need to make to provide better anonymity, and what we'll be trading off.
Part one: The research questions
In Tor, each client selects a few relays at random, and chooses only from those relays when making the first hop of each circuit. This entry guard design helps in three ways:
First, entry guards protect against the "predecessor attack": if Alice (the user) instead chose new relays for each circuit, eventually an attacker who runs a few relays would be her first and last hop. With entry guards, the risk of end-to-end correlation for any given circuit is the same, but the cumulative risk for all her circuits over time is capped.
Second, they help to protect against the "denial of service as denial of anonymity" attack, where an attacker who runs quite a few relays fails any circuit that he's a part of and that he can't win against, forcing Alice to generate more circuits and thus increasing the overall chance that the attacker wins. Entry guards greatly reduce the risk, since Alice will never choose outside of a few nodes for her first hop.
Third, entry guards raise the startup cost to an adversary who runs relays in order to trace users. Without entry guards, the attacker can sign up some relays and immediately start having chances to observe Alice's circuits. With them, new adversarial relays won't have the Guard flag so won't be chosen as the first hop of any circuit; and even once they earn the Guard flag, users who have already chosen guards won't switch away from their current guards for quite a while.
In August 2011, I posted these four open research questions around guard rotation parameters:
- Natural churn: For an adversary that controls a given number of relays, if the user only replaces her guards when the current ones become unavailable, how long will it take until she's picked an adversary's guard?
- Artificial churn: How much more risk does she introduce by intentionally switching to new guards before she has to, to load balance better?
- Number of guards: What are the tradeoffs in performance and anonymity from picking three guards vs two or one? By default Tor picks three guards, since if we picked only one then some clients would pick a slow one and be sad forever. On the other hand, picking only one makes users safer.
- Better Guard flag assignment: If we give the Guard flag to more or different relays, how much does it change all these answers?
For reference, Tor 0.2.3's entry guard behavior is "choose three guards, adding another one if two of those three go down but going back to the original ones if they come back up, and also throw out (aka rotate) a guard 4-8 weeks after you chose it." I'll discuss in "Part three" of this post what changes we should make to improve this policy.
Part two: Recent research papers
Tariq Elahi, a grad student in Ian Goldberg's group in Waterloo, began to answer the above research questions in his paper Changing of the Guards: A Framework for Understanding and Improving Entry Guard Selection in Tor (published at WPES 2012). His paper used eight months of real-world historical Tor network data (from April 2011 to December 2011) and simulated various guard rotation policies to see which approaches protect users better.
Tariq's paper considered a quite small adversary: he let all the clients pick honest guards, and then added one new small guard to the 800 or so existing guards. The question is then what fraction of clients use this new guard over time. Here's a graph from the paper, showing (assuming all users pick three guards) the vulnerability due to natural churn ("without guard rotation") vs natural churn plus also intentional guard rotation:
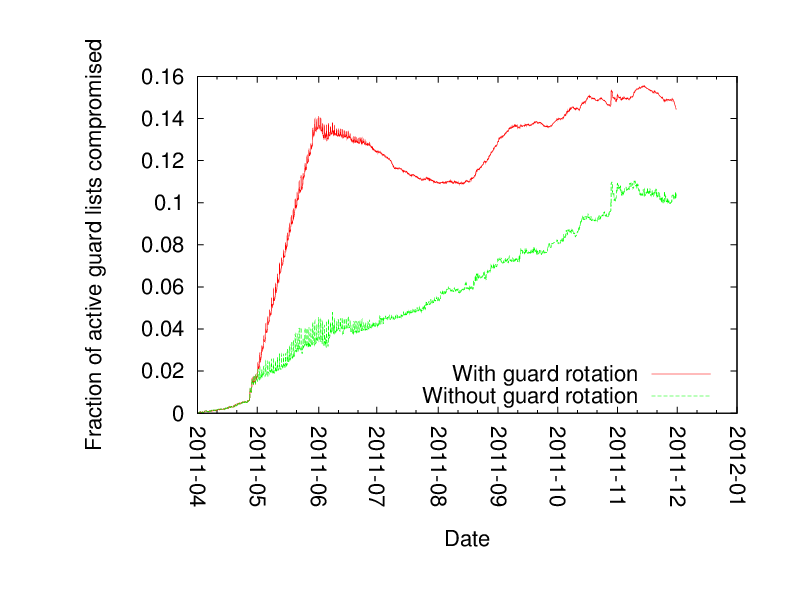
In this graph their tiny guard node, in the "without guard rotation" scenario, ends up getting used by about 3% of the clients in the first few months, and gets up to 10% by the eight-month mark. The more risky scenario — which Tor uses today — sees the risk shoot up to 14% in the first few months. (Note that the y-axis in the graph only goes up to 16%, mostly because the attacking guard is so small.)
The second paper to raise the issue is from Alex Biryukov, Ivan Pustogarov, and Ralf-Philipp Weinmann in Luxembourg. Their paper Trawling for Tor Hidden Services: Detection, Measurement, Deanonymization (published at Oakland 2013) mostly focuses on other attacks (like how to censor or track popularity of hidden services), but their Section VI.C. talks about the "run a relay and wait until the client picks you as her guard" attack. In this case they run the numbers for a much larger adversary: if they run 13.8% of the Tor network for eight months there's more than a 90% chance of a given hidden service using their guard sometime during that period. That's a huge fraction of the network, but it's also a huge chance of success. And since hidden services in this case are basically the same as Tor clients (they choose guards and build circuits the same way), it's reasonable to conclude that their attack works against normal clients too so long as the clients use Tor often enough during that time.
I should clarify three points here.
First clarifying point: Tariq's paper makes two simplifying assumptions when calling an attack successful if the adversary's relay *ever* gets into the user's guard set. 1) He assumes that the adversary is also either watching the user's destination (e.g. the website she's going to), or he's running enough exit relays that he'll for sure be able to see the correponding flow out of the Tor network. 2) He assumes that the end-to-end correlation attack (matching up the incoming flow to the outgoing flow) is instantaneous and perfect. Alex's paper argues pretty convincingly that these two assumptions are easier to make in the case of attacking a hidden service (since the adversary can dictate how often the hidden service makes a new circuit, as well as what the traffic pattern looks like), and the paper I describe next addresses the first assumption, but the second one ("how successful is the correlation attack at scale?" or maybe better, "how do the false positives in the correlation attack compare to the false negatives?") remains an open research question.
Researchers generally agree that given a handful of traffic flows, it's easy to match them up. But what about the millions of traffic flows we have now? What levels of false positives (algorithm says "match!" when it's wrong) are acceptable to this attacker? Are there some simple, not too burdensome, tricks we can do to drive up the false positives rates, even if we all agree that those tricks wouldn't work in the "just looking at a handful of flows" case?
More precisely, it's possible that correlation attacks don't scale well because as the number of Tor clients grows, the chance that the exit stream actually came from a different Tor client (not the one you're watching) grows. So the confidence in your match needs to grow along with that or your false positive rate will explode. The people who say that correlation attacks don't scale use phrases like "say your correlation attack is 99.9% accurate" when arguing it. The folks who think it does scale use phrases like "I can easily make my correlation attack arbitrarily accurate." My hope is that the reality is somewhere in between — correlation attacks in the current Tor network can probably be made plenty accurate, but perhaps with some simple design changes we can improve the situation. In any case, I'm not going to try to tackle that research question here, except to point out that 1) it's actually unclear in practice whether you're done with the attack if you get your relay into the user's guard set, or if you are now faced with a challenging flow correlation problem that could produce false positives, and 2) the goal of the entry guard design is to make this issue moot: it sure would be nice to have a design where it's hard for adversaries to get into a position to see both sides, since it would make it irrelevant how good they are at traffic correlation.
Second clarifying point: it's about the probabilities, and that's intentional. Some people might be scared by phrases like "there's an x% chance over y months to be able to get an attacker's relay into the user's guard set." After all, they reason, shouldn't Tor provide absolute anonymity rather than probabilistic anonymity? This point is even trickier in the face of centralized anonymity services that promise "100% guaranteed" anonymity, when what they really mean is "we could watch everything you do, and we might sell or give up your data in some cases, and even if we don't there's still just one point on the network where an eavesdropper can learn everything." Tor's path selection strategy distributes trust over multiple relays to avoid this centralization. The trouble here isn't that there's a chance for the adversary to win — the trouble is that our current parameters make that chance bigger than it needs to be.
To make it even clearer: the entry guard design is doing its job here, just not well enough. Specifically, *without* using the entry guard design, an adversary who runs some relays would very quickly find himself as the first hop of one of the user's circuits.
Third clarifying point: we're considering an attacker who wants to learn if the user *ever* goes to a given destination. There are plenty of reasonable other things an attacker might be trying to learn, like building a profile of many or all of the user's destinations, but in this case Tariq's paper counts a successful attack as one that confirms (subject to the above assumptions) that the user visited a given destination once.
And that brings us to the third paper, by Aaron Johnson et al: Users Get Routed: Traffic Correlation on Tor by Realistic Adversaries (upcoming at CCS 2013). This paper ties together two previous series of research papers: the first is "what if the attacker runs a relay?" which is what the above two papers talked about, and the second is "what if the attacker can watch part of the Internet?"
The first part of the paper should sound pretty familiar by now: they simulated running a few entry guards that together make up 10% of the guard capacity in the Tor network, and they showed that (again using historical Tor network data, but this time from October 2012 to March 2013) the chance that the user has made a circuit using the adversary's relays is more than 80% by the six month mark.
In this case their simulation includes the adversary running a fast exit relay too, and the user performs a set of sessions over time. They observe that the user's traffic passes over pretty much all the exit relays (which makes sense since Tor doesn't use an "exit guard" design). Or summarizing at an even higher level, the conclusion is that so long as the user uses Tor enough, this paper confirms the findings in the earlier two papers.
Where it gets interesting is when they explain that "the adversary could run a relay" is not the only risk to worry about. They build on the series of papers started by "Location Diversity in Anonymity Networks" (WPES 2004), "AS-awareness in Tor path selection" (CCS 2009), and most recently "An Empirical Evaluation of Relay Selection in Tor" (NDSS 2013). These papers look at the chance that traffic from a given Tor circuit will traverse a given set of Internet links.
Their point, which like all good ideas is obvious in retrospect, is that rather than running a guard relay and waiting for the user to switch to it, the attacker should instead monitor as many Internet links as he can, and wait for the user to use a guard such that traffic between the user and the guard passes over one of the links the adversary is watching.
This part of the paper raises as many questions as it answers. In particular, all the users they considered are in or near Germany. There are also quite a few Tor relays in Germany. How much of their results here can be explained by pecularities of Internet connectivity in Germany? Are their results predictive in any way about how users on other continents would fare? Or said another way, how can we learn whether their conclusion shouldn't instead be "German Tor users are screwed, because look how Germany's Internet topology is set up"? Secondly, their scenario has the adversary control the Autonomous System (AS) or Internet Exchange Point (IXP) that maximally deanonymizes the user (they exclude the AS that contains the user and the AS that contains her destinations). This "best possible point to attack" assumption a) doesn't consider how hard it is to compromise that particular part of the Internet, and b) seems like it will often be part of the Internet topology near the user (and thus vary greatly depending on which user you're looking at). And third, like the previous papers, they think of an AS as a single Internet location that the adversary is either monitoring or not monitoring. Some ASes, like large telecoms, are quite big and spread out.
That said, I think it's clear from this paper that there *do* exist realistic scenarios where Tor users are at high risk from an adversary watching the nearby Internet infrastructure and/or parts of the Internet backbone. Changing the guard rotation parameters as I describe in "Part three" below will help in some of these cases but probably won't help in all of them. The canonical example that I've given in talks about "a person in Syria using Tor to visit a website in Syria" remains a very serious worry.
The paper also makes me think about exit traffic patterns, and how to better protect people who use Tor for only a short period of time: many websites pull in resources from all over, especially resources from centralized ad sites. This risk (that it greatly speeds the rate at which an adversary watching a few exit points — or heck, a few ad sites — will be able to observe a given user's exit traffic) provides the most compelling reason I've heard so far to ship Tor Browser Bundle with an ad blocker — or maybe better, with something like Request Policy that doesn't even touch the sites in the first place. On the other hand, Mike Perry still doesn't want to ship an ad blocker in TBB, since he doesn't want to pick a fight with Google and give them even more of a reason to block/drop all Tor traffic. I can see that perspective too.
Part three: How to fix it
Here are five steps we should take, in rough order of how much impact I think each of them would have on the above attacks.
If you like metaphors, think of each time you pick a new guard as a coin flip (heads you get the adversary's guard, tails you're safe this time), and the ideas here aim to reduce both the number and frequency of coin flips.
Fix 1: Tor clients should use fewer guards.
The primary benefit to moving to fewer guards is that there are fewer coin flips every time you pick your guards.
But there's a second benefit as well: right now your choice of guards acts as a kind of fingerprint for you, since very few other users will have picked the same three guards you did. (This fingerprint is only usable by an attacker who can discover your guard list, but in some scenarios that's a realistic attack.) To be more concrete: if the adversary learns that you have a particular three guards, and later sees an anonymous user with exactly the same guards, how likely is it to be you? Moving to two guards helps the math a lot here, since you'll overlap with many more users when everybody is only picking two.
On the other hand, the main downside is increased variation in performance. Here's Figure 10 from Tariq's paper:
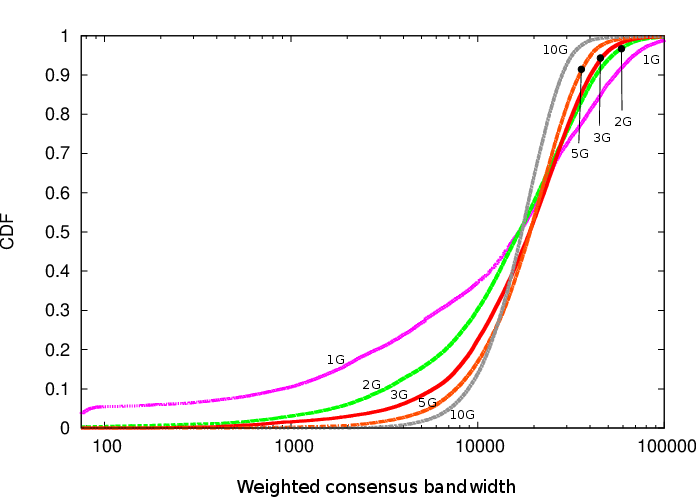
"Farther to the right" is better in this graph. When you pick three guards (the red line), the average speed of your guards is pretty good (and pretty predictable), since most guards are pretty fast and it's unlikely you'll pick slow ones for all three. However, when you only pick only one guard (the purple line), the odds go up a lot that you get unlucky and pick a slow one. In more concrete numbers, half of the Tor users will see up to 60% worse performance.
The fix of course is to raise the bar for becoming a guard, so every possible guard will be acceptably fast. But then we have fewer guards total, increasing the vulnerability from other attacks! Finding the right balance (as many guards as possible, but all of them fast) is going to be an ongoing challenge. See Brainstorm tradeoffs from moving to 2 (or even 1) guards (ticket 9273) for more discussion.
Switching to just one guard will also preclude deploying Conflux, a recent proposal to improve Tor performance by routing traffic over multiple paths in parallel. The Conflux design is appealing because it not only lets us make better use of lower-bandwidth relays (which we'll need to do if we want to greatly grow the size of the Tor network), but it also lets us dynamically adapt to congestion by shifting traffic to less congested routes. Maybe some sort of "guard family" idea can work, where a single coin flip chooses a pair of guards and then we split our traffic over them. But if we want to avoid doubling the exposure to a network-level adversary, we might want to make sure that these two guards are near each other on the network — I think the analysis of the network-level adversary in Aaron's paper is the strongest argument for restricting the variety of Internet paths that traffic takes between the Tor client and the Tor network.
This discussion about reducing the number of guards also relates to bridges: right now if you configure ten bridges, you round-robin over all of them. It seems wise for us to instead use only the first bridge in our bridge list, to cut down on the set of Internet-level adversaries that get to see the traffic flows going into the Tor network.
Fix 2: Tor clients should keep their guards for longer.
In addition to choosing fewer guards, we should also avoid switching guards so often. I originally picked "one or two months" for guard rotation since it seemed like a very long time. In Tor 0.2.4, we've changed it to "two or three months". But I think changing the guard rotation period to a year or more is probably much wiser, since it will slow down the curves on all the graphs in the above research papers.
I asked Aaron to make a graph comparing the success of an attacker who runs 10% of the guard capacity, in the "choose 3 guards and rotate them every 1-2 months" case and the "choose 1 guard and never rotate" case:
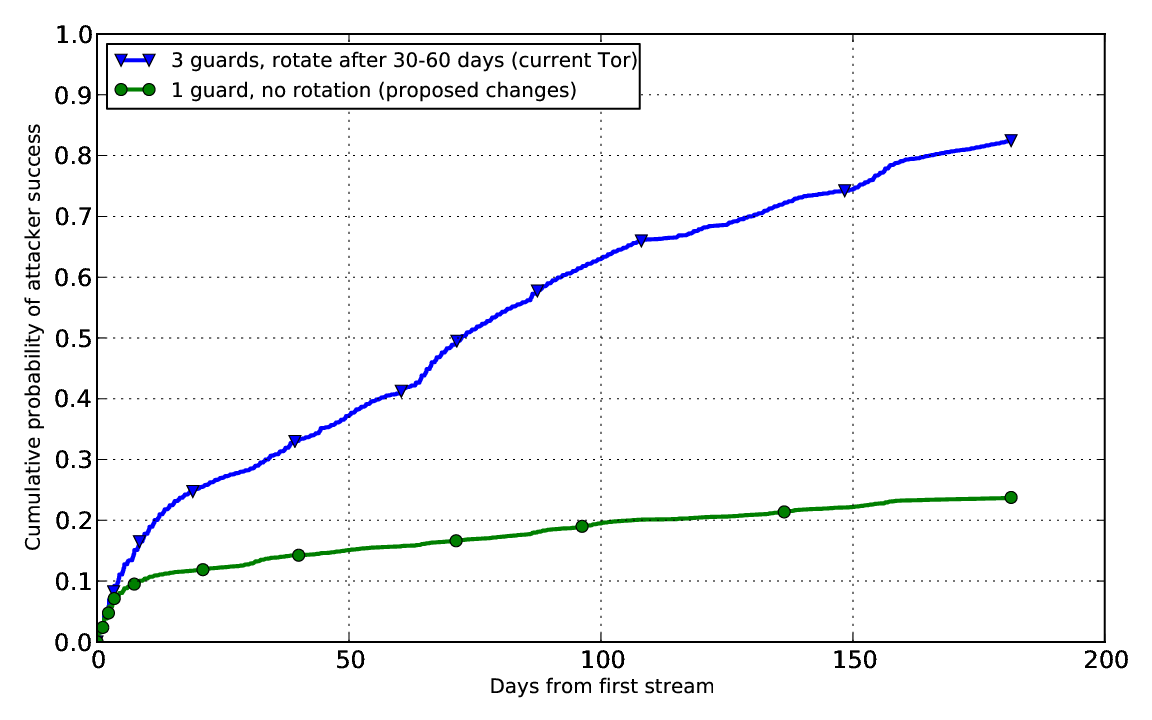
In the "3 guard" case (the blue line), the attacker's success rate rapidly grows to about 25%, and then it steadily grows to over 80% by the six month mark. The "1 guard" case (green line), on the other hand, grows to 10% (which makes sense since the adversary runs 10% of the guards), but then it levels off and grows only slowly as a function of network churn. By the six month mark, even this very large adversary's success rate is still under 25%.
So the good news is that by choosing better guard rotation parameters, we can almost entirely resolve the vulnerabilities described in these three papers. Great!
Or to phrase it more as a research question, once we get rid of this known issue, I'm curious how the new graphs over time will look, especially when we have a more sophisticated analysis of the "network observer" adversary. I bet there are some neat other attacks that we'll need to explore and resolve, but that are being masked by the poor guard parameter issue.
However, fixing the guard rotation period issue is alas not as simple as we might hope. The fundamental problem has to do with "load balancing": allocating traffic onto the Tor network so each relay is used the right amount. If Tor clients choose a guard and stick with it for a year or more, then old guards (relays that have been around and stable for a long time) will see a lot of use, and new guards will see very little use.
I wrote a separate blog post to provide background for this issue: "The lifecycle of a new relay". Imagine if the ramp-up period in the graph from that blog post were a year long! People would set up fast relays, they would get the Guard flag, and suddenly they'd see little to no traffic for months. We'd be throwing away easily half of the capacity volunteered by relays.
One approach to resolving the conflict would be for the directory authorities to track how much of the past n months each relay has had the Guard flag, and publish a fraction in the networkstatus consensus. Then we'd teach clients to rebalance their path selection choices so a relay that's been a Guard for only half of the past year only counts 50% as a guard in terms of using that relay in other positions in circuits. See Load balance right when we have higher guard rotation periods (ticket 9321) for more discussion, and see Raise our guard rotation period (ticket 8240) for earlier discussions.
Yet another challenge here is that sticking to the same guard for a year gives plenty of time for an attacker to identify the guard and attack it somehow. It's particularly easy to identify the guard(s) for hidden services currently (since as mentioned above, the adversary can control the rate at which hidden services make new circuits, simply by visiting the hidden service), but similar attacks can probably be made to work against normal Tor clients — see e.g. the http-level refresh tricks in How Much Anonymity does Network Latency Leak? This attack would effectively turn Tor into a network of one-hop proxies, to an attacker who can efficiently enumerate guards. That's not a complete attack, but it sure does make me nervous.
One possible direction for a fix is to a) isolate streams by browser tab, so all the requests from a given browser tab go to the same circuit, but different browser tabs get different circuits, and then b) stick to the same three-hop circuit (i.e. same guard, middle, and exit) for the lifetime of that session (browser tab). How to slow down guard enumeration attacks is a tough and complex topic, and it's too broad for this blog post, but I raise the issue here as a reminder of how interconnected anonymity attacks and defenses are. See Slow Guard Discovery of Hidden Services and Clients (ticket 9001) for more discussion.
Fix 3: The Tor code should better handle edge cases where you can't reach your guard briefly.
If a temporary network hiccup makes your guard unreachable, you switch to another one. But how long is it until you switch back? If the adversary's goal is to learn whether you ever go to a target website, then even a brief switch to a guard that the adversary can control or observe could be enough to mess up your anonymity.
Tor clients fetch a new networkstatus consensus every 2-4 hours, and they are willing to retry non-running guards if the new consensus says they're up again.
But I think there are a series of little bugs and edge cases where the Tor client abandons a guard more quickly than it should. For example, we mark a guard as failed if any of our circuit requests time out before finishing the handshake with the first hop. We should audit both the design and the source code with an eye towards identifying and resolving these issues.
We should also consider whether an adversary can *induce* congestion or resource exhaustion to cause a target user to switch away from her guard. Such an attack could work very nicely coupled with the guard enumeration attacks discussed above.
Most of these problems exist because in the early days we emphasized reachability ("make sure Tor works") over anonymity ("be very sure that your guard is gone before you try another one"). How should we handle this tradeoff between availability and anonymity: should you simply stop working if you've switched guards too many times recently? I imagine different users would choose different answers to that tradeoff, depending on their priorities. It sounds like we should make it easier for users to select "preserve my anonymity even if it means lower availability". But at the same time, we should remember the lessons from Anonymity Loves Company: Usability and the Network Effect about how letting users choose different settings can make them more distinguishable.
Fix 4: We need to make the network bigger.
We've been working hard in recent years to get more relay capacity. The result is a more than four-fold increase in network capacity since 2011:
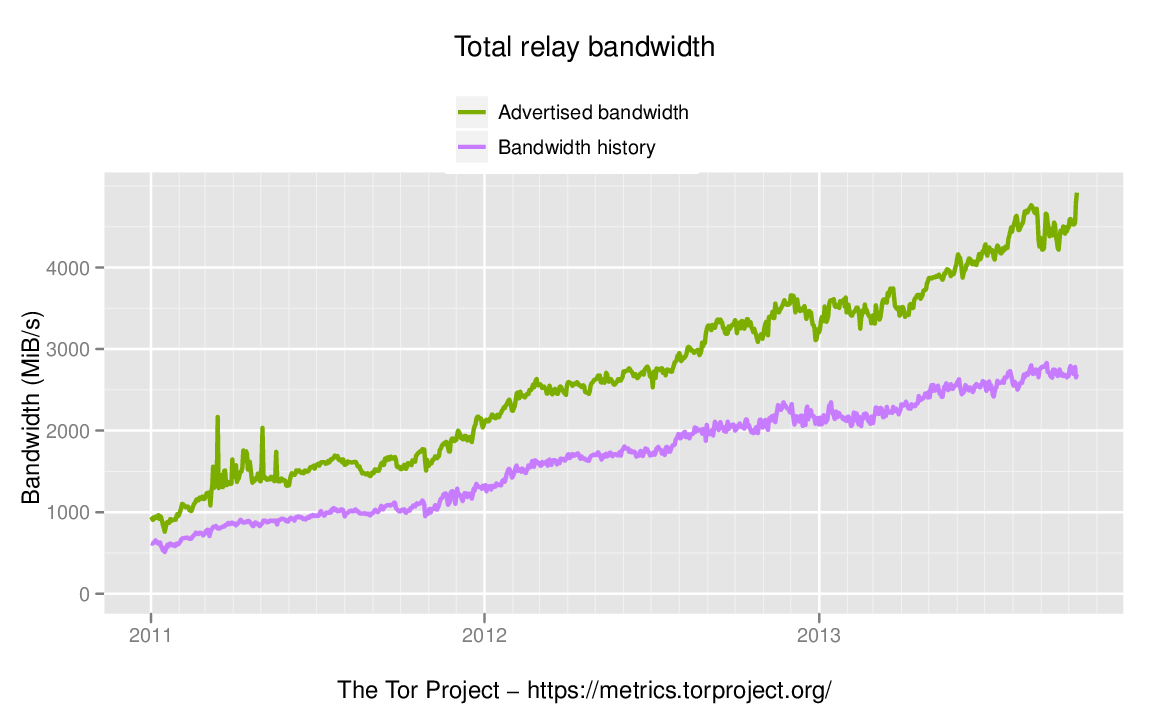
As the network grows, an attacker with a given set of resources will have less success at the attacks described in this blog post. To put some numbers on it, while the relay adversary in Aaron's paper (who carries 660mbit/s of Tor traffic) represented 10% of the guard capacity in October 2012, that very same attacker would have been 20% of the guard capacity in October 2011. Today that attacker is about 5% of the guard capacity. Growing the size of the network translates directly into better defense against these attacks.
However, the analysis is more complex when it comes to a network adversary. Just adding more relays (and more relay capacity) doesn't always help. For example, adding more relay capacity in a part of the network that the adversary is already observing can actually *decrease* anonymity, because it increases the fraction the adversary can watch. We discussed many of these issues in the thread about turning funding into more exit relays. For more details about the relay distribution in the current Tor network, check out Compass, our tool to explore what fraction of relay capacity is run in each country or AS. Also check out Lunar's relay bubble graphs.
Yet another open research question in the field of anonymous communications is how the success rate of a network adversary changes as the Tor network changes. If we were to plot the success rate of the *relay* adversary using historical Tor network data over time, it's pretty clear that the success rate would be going down over time as the network grows. But what's the trend for the success rate of the network adversary over the past few years? Nobody knows. It could be going up or down. And even if it is going down, it could be going down quickly or slowly.
(Read more in Research problem: measuring the safety of the Tor network where I describe some of these issues in more detail.)
Recent papers have gone through enormous effort to get one, very approximate, snapshot of the Internet's topology. Doing that effort retroactively and over long and dynamic time periods seems even more difficult and more likely to introduce errors.
It may be that the realities of Internet topology centralization make it so that there are fundamental limits on how much safety Tor users can have in a given network location. On the other hand, researchers like Aaron Johnson are optimistic that "network topology aware" path selection can improve Tor's protection against this style of attack. Much work remains.
Fix 5: We should assign the guard flag more intelligently.
In point 1 above I talked about why we need to raise the bar for becoming a guard, so all guards can provide adequate bandwidth. On the other hand, having fewer guards is directly at odds with point 4 above.
My original guard rotation parameters blog post ends with this question: what algorithm should we use to assign Guard flags such that a) we assign the flag to as many relays as possible, yet b) we minimize the chance that Alice will use the adversary's node as a guard?
We should use historical Tor network data to pick good values for the parameters that decide which relays become guards. This remains a great thesis topic if somebody wants to pick it up.
Part four: Other thoughts
What does all of this discussion mean for the rest of Tor? I'll close by trying to tie this blog post to the broader Tor world.
First, all three of these papers come from the Tor research community, and it's great that Tor gets such attention. We get this attention because we put so much effort into making it easy for researchers to analyze Tor: we've worked closely with these authors to help them understand Tor and focus on the most pressing research problems.
In addition, don't be fooled into thinking that these attacks only apply to Tor: using Tor is still better than using any other tool, at least in quite a few of these scenarios. That said, some other attacks in the research literature might be even easier than the attacks discussed here. These are fast-moving times for anonymity research. "Maybe you shouldn't use the Internet then" is still the best advice for some people.
Second, the Tails live CD doesn't use persistent guards. That's really bad I think, assuming the Tails users have persistent behavior (which basically all users do). See their ticket 5462.
Third, the network-level adversaries rely on being able to recognize Tor flows. Does that argue that using pluggable transports, with bridges, might change the equation if it stops the attacker from recognizing Tor users?
Fourth, I should clarify that I don't think any of these large relay-level adversaries actually exist, except as a succession of researchers showing that it can be done. (GCHQ apparently ran a small number of relays a while ago, but not in a volume or duration that would have enabled this attack.) Whereas I *do* think that the network-level attackers exist, since they already invested in being able to surveil the Internet for other reasons. So I think it's great that Aaron's paper presents the dual risks of relay adversaries and link adversaries, since most of the time when people are worrying about one of them they're forgetting the other one.
Fifth, there are still some ways to game the bandwidth authority measurements (here's the spec) into giving you more than your fair share of traffic. Ideally we'd adapt a design like EigenSpeed so it can measure fast relays both robustly and accurately. This question also remains a great thesis topic.
And finally, as everybody wants to know: was this attack how "they" busted recent hidden services (Freedom Hosting, Silk Road, the attacks described in the latest Guardian article)? The answer is apparently no in each case, which means the techniques they *did* use were even *lower* hanging fruit. The lesson? Security is hard, and you have to get it right at many different levels.
Comments
Please note that the comment area below has been archived.
I'm going to be offline
I'm going to be offline starting tomorrow for about a week, so please be patient with the comment section. Thanks!
I've read all of these
I've read all of these papers, and I think a target for near-term research should be "is the harm to your anonymity if you choose a malicious guard (and thus use it for 100% of your connections for some interval), perhaps, worse than the harm to your anonymity if you don't have a guard at all (and thus some random-but-small fraction of your connections over that interval are via a malicious entry node)?
I worry that by doubling down on the guard strategy every time someone shows that it doesn't actually protect users all that well from malicious entry nodes, we are actually playing into the adversary's hand.
-- Zack
This is an interesting
This is an interesting question whose answer that depends the Tor activity of a user and what exactly the user wants to keep private. Let's consider some scenarios:
As you can tell, for the uses of Tor that seem most likely to me, users are better off giving up none or all of the activity to a malicious guard. Users are trying to protect behavior rather than TCP connections. Behavior operates on the order of weeks, months, and years, which - not coincidentally - is the length of time that a given guard is used.
ajohnson*
*Full disclosure: I am an author of the "Users Get Routed" paper discussed in the post.
Right. See also my
Right. See also my discussion in the "third clarifying point" paragraph above.
In general it seems to me that the advertising companies are doing really well at the "see a sample of a user's behavior and piece together the rest of it" problem. That is, if Google only got to see a random 10% of a user's traffic, all their algorithms (to track, recognize, and predict people) would probably still work fine.
That word *random* is key though. If we could make it so the subset they see never includes certain behaviors, then we'd be on to something. That's why I'm still nervous that entry guards remain the same despite clicking 'new identity' and despite using stream isolation features. On the other hand, to an entry guard, the IP address is already a recognizable feature that isn't so easy to change just by clicking a button. Our best bet would be to use an anonymity system to reach Tor -- but even then whatever remains as the equivalent of the first hop would still need something like entry guards, assuming we're aiming for a system that scales to millions of people and doesn't involve having each user set up 'trusted' infrastructure (whatever trusted would even mean on this fine Internet we have).
So, after this back-and-forth, my conclusion is that I agree entry guards aren't satisfying, but so far nobody has anything better.
Roger, thanks for this
Roger, thanks for this INCREDIBLE POST! Since I've recently been thinking about some related things, I wanted to post something very preliminary that I'd planned to write up for tor-talk on what could be called "bandwidth concentration"--or how relationships between the fastest and slowest relays might affect some of the attacks Roger described above.
I was curious to take a crude look at the relationship between bandwidth and uptime for stable running Tor relays, based on data from http://torstatus.blutmagie.de/index.php, compass.torproject.org, and metrics.torproject.org on October 15th.
For stable running relays with the guard flag, I found that:
-mean uptime was 36.4 days for the 1430 listed, with a mean of 663KB/s advertised
-the top 50% of bandwidth is concentrated in the 114 fastest routers (8% of the total), which had an average uptime of 29.0 days
Based on the guard probabilities at compass.torproject.org:
-there's a 50% probability of using one of the 84 fastest relays with the guard flag
-there's a 25% probability of using one of the 26 fastest relays with the guard flag
For stable running relays with neither the guard nor the exit flags, I found that:
-mean uptime was 23.3 days for the 957 listed, with a mean of 208.2KB/s advertised
-the top 50% of bandwidth is concentrated in the 26 fastest relays with neither the guard nor exit flags
-the top 25% of bandwidth is concentrated in the 9 fastest relays with neither the guard nor the exit flags
Based on the middle probabilities at compass.torproject.org:
-there's a 50% probability of a non-exit, non-guard middle relay being one of the
For stable running relays with the exit flag, I found that:
-mean uptime was 41.0 days for the 591 listed, with a mean of 1,468KB/s advertised
-the top 50% of bandwidth is concentrated in the 29 fastest relays (4.9% of the total), which had an average uptime of 22.1 days
-Looking at each of these relays in Atlas, I was pleasantly surprised to see that all but ArachnideFR35 and csailmitexit appeared to be running 0.2.4.17x, all on Linux (except DFRI0 on FreeBSD).
Based on the exit probabilities at compass.torproject.org:
-there's a 50% probability of using one of the 31 fastest relays with the exit flag
-there's a 25% probability of using one of the 11 fastest relays with the exit flag
There's much to be said about the numbers above (coming soon), but Roger's discussion raises different questions for me: is there a way to--ideally based on on-the-fly analyses of Tor network metrics--allow for more educated user input in terms of choosing guard policies tailored to the threat models they care most about (and to do so without being incredibly sophisticated technically)? At the limit, improving any given users' chances of defending against a threat like a GPA slurping up traffic from the 26 fastest guards and 11 fastest exits (25% of the bandwidth of each) with a NARUS will be different than the design and user choices that defend against a different threat model. Especially if it can be done without degrading performance, I wonder if diversifying the threat models Tor defends against at the user level based on analytics of the network at any given moment could improve overall anonymity. Hope to flesh out a few of these thoughts soon, but thank you for such a thoughtful post.
More research here is
More research here is definitely needed! This is exactly why we set up tools like Compass.
Here are some early thoughts:
- Rather than looking at uptime, looking at WFU and MTBF is hopefully going to give you better insights. Uptime is too much a function of recent events (like new Tor releases).
- Don't confuse "chance of picking a non-exit non-guard relay" with "chance of picking that relay for your middle hop". Both guards and exits can be picked for your middle hop, just with proportionally less chance compared to the available bandwidth in each category.
- Giving the Guard flag to more relays can counterintuitively *increase* the diversity for your middle hop, by making it more likely that relays with the Guard flag will be picked for your middle hop. Unless I'm wrong -- somebody should prove or disprove.
- As for whether multiple path selection strategies could play well together, see http://freehaven.net/anonbib/#ccs2011-trust
for some earlier work there. The key is to avoid the pitfall that so many other papers fall into, where they compare some path selection strategy to Tor's current strategy, show that one user using the new one can outperform (for whatever metric) the old ones, and then conclude that clearly everybody should use the new one. Most papers make this mistake when considering performance improvements, but there are plenty that get it wrong for anonymity metrics too.
Hi, statistically meaning,
Hi, statistically meaning, could be a good idea to Strictly ExcludeExitNodes from us || uk || both? [ok is a really bad idea (for the traffic but not only..) if the torrc was shipped with that enabled, but what if a single user adds a line like that into the torrc? bring more or less problems?] thanx in advance ;-)
Check
Check out
http://freehaven.net/anonbib/#ccs2011-trust
for a paper that starts to explore the question of selecting your paths different from most users.
My current intuition is that for the specific config change you describe, you'll be harming your diversity (aka anonymity) a lot, for an unclear amount of gain.
Respectfully, this argument
Respectfully, this argument about the potential adverse effects of diversity strikes me as a bit of a red herring argument in the way it's presented sometimes.
You're 100% right about the dynamics between network diversity & potential selectors that could be used to de-identify users, but I also think it's important to explicitly consider that this dynamic always plays out on the margin in practice, and for specific individuals.
The reality is that at least some Tor users are already doing a bunch of different things--from using adblock edge to blocking javascript to using VPN tunnels--all of which could be used to suss out a user's behavioral and other fingerprints. So if ad company X is trying to de-anonymize Tor users behaviorally through nytimes.com once they navigate to gmail.com, it might matter a LOT more how many pages people browse between "new identities" than whether they have a set of 2 guards instead of 20. And why would a GPA need to intercept communications if they can just subpoena a third party's analytics logs to get very close to de-anonymization?
I concede that Tor has a clearly specified threat model and that I haven't fully considered those details here, but I also think most Tor users in most use cases don't go down a mental checklist to compare their personal threat model and Tor's default attack surface before tweaking configurations or their browsing behaviors every single time they visit every single site. I take the point that there's a legitimate "not my department" argument for Tor to make about relay-facing network parameters vs. tracking once traffic exits the network, but having so many users tied to a browser in a specific default configuration makes it more complicated.
I actually agree with Roger, except to add that for some users in some circumstances, the more important question is what any potential change to the guard system adds or subtracts from a given user's potential attack surface(s) as defined by a given threat model or threat models as defined (or hopefully at least clearly understood) by the user. It's not reasonable to expect Tor to cater to everyone, but it's also unwise to implicitly assume that technically literate users aren't already doing things like this. If configuration diversity is already happening, perhaps it's worth considering the potential effects of that behavior on other users' anonymity to the extent possible.
My only strong preference would be to make these decisions from a strong analytical base, and ideally based on current network conditions.
Thanks again, Roger, for an insightful and thoughtful post.
As for whether number of
As for whether number of entry guards is the most critical parameter to improving Tor's security, I agree that in many cases it isn't -- resistance to browser exploits, for example, is a fine area to work on in parallel (and has been shown to be the lower hanging fruit in recent real-world cases).
That said, with the typical turnaround time of 2-4 years between when I figure out how to phrase the research question well and when the answers start arriving in the form of peer-reviewed research papers, we definitely have to pipeline some of this work and enlist the broader community to help us wrestle with the underlying theory.
And to answer your last point about "make the decisions from a strong analytical base", that's exactly the problem right now -- nobody has one, so a small number of technical users start fiddling with things, we warn them that in the general sense they might be hurting themselves more than they're helping themselves, and .. here we are. More answers would be great!
If you really want to
If you really want to improve your Tor anomity software,
why don't support:
1. Increase more hop (3 is not good. ex. OverwriteDefaultHopCounts 5)
Why only 3 nodes?
XTor->Omnify->Randevo
XTor->Insid->Stupid
Every time I connect to tor, XTor come first(this is an example, not a real node name).
If XTor is an NSA, this means only 2 hops.
So please let users to set how many hops they use (AdvOR support this, why not official Tor!!)
2. Add an option: "DontUseSameCountry true"
Latvia->China->China
This is bad chain. AdvOR support this, why not official Tor!!
3. Auto-ban-badass feature (share ExcludeNode information!)
I think most of these are
I think most of these are poor ideas that will lead to worse anonymity. (Just because some guy wrote a fork called "advor" does not mean he has read the literature or thought about the implications of his features.)
For the initial question of more hops, see
https://www.torproject.org/docs/faq#ChoosePathLength
and also re-read this blog post a few more times since I think you missed a lot of the subtle points.
For the country-level routing, a) read the CCS 2013 paper again and reconsider network-level adversaries, and b) see http://freehaven.net/anonbib/#ccs2011-trust for more analysis of cases where you want to choose your paths differently than mainstream users, and pitfalls you'll run into.
Hi, I was wondering if you
Hi, I was wondering if you could talk about how much would change if Tor stopped promising "low latency." From what I understand about mixmailers, they wait until they have gathered multiple requests from different places before sending them all out at the same time so that it becomes difficult to perform latency correlation between entrance and exit of the network.
Obviously, losing latency would make current web browsing worse and it would probably mean that each relay would need to store packets for some amount of time, (which now that I think about it, has got to be a pretty drastic change in design. And I probably couldn't wait even 15 min to get a webpage). Would it work to just add the option to ask any relay in the circuit to hold onto a packet for X secs or so before passing it on?
If we dropped low-latency,
If we dropped low-latency, we'd lose all our users, and then while we could provide better anonymity in theory, we would not be able to in practice. See
http://www.mail-archive.com/liberationtech@lists.stanford.edu/msg00022…
for the longer version of the story.
Then check out "Blending Different Latency Traffic with Alpha-Mixing":
http://freehaven.net/anonbib/#alpha-mixing:pet2006
It's exactly about this goal of mixing higher-latency traffic with lower-latency traffic. Unfortunately, the alpha-mixing analysis is still about message-oriented systems (like remailers), not flow-oriented systems (like onion routing). I fear it loses a lot of its charm when you try to squeeze it into a flow-oriented model. But please prove me wrong!
With the current advice of
With the current advice of installing Tor Browser Bundle upgrades from scratch, aren't the guards of most Tor users renewed with each TBB upgrade (often required for security reasons), anyway?
If so, please, TBB developers, make in-place upgrades the preferred method, so that the core Tor guard parameters can be used.
Yes indeed!
Yes indeed! See
https://lists.torproject.org/pipermail/tor-talk/2013-September/029792.h…
Keep an eye on https://trac.torproject.org/projects/tor/ticket/4234 for one possible fix.
For things like streaming,
For things like streaming, downloads, chat, email it is often no problem to have a 2~10 second delay. It could be possible for the client to ask for a delay at every hop. For example: client -> 1 -> 5 -> 4 -> clearnet.
A target delay could also be specified by a mean and variance, and could be followed by a burst (300kb/s) or throttle (30kb/s).
Would such a design allow for more anonymity?
If there is a delay, then the following might increase anonymity:
- Use different path to send/receive information or use split paths.
- Have the nodes inflate bandwidth (by appending 0x0 to data) from certain connections, such that different connections look very similar (e.g. multiple connections at 64 kb/s) Other nodes then remove the trailing 0x0 bytes, and possibly inflate according to the other connections that they serve.
By introducing a delay it might also be possible for exit nodes to compress the data, if it is not encrypted. For example for youtube or some texts/source code.
R.
Sounds like a great thesis
Sounds like a great thesis topic. I don't want to say no, but nobody's been able to say yes yet.
My only hint would be to focus on synchronization, not delay. It isn't about how long you have to wait -- it's about how many other flows look (from the adversary's perspective) like your flow.
Oh, and I guess my other hint would be to read through anonbib and to get involved in the PETS community.
Yes, I want increase more
Yes, I want increase more hop too, because I use (local tor)Bridge to connect tor network like this:
Me --> local(192.168.1.1) tor Bridge --> X1 --> X2
so I want increase to 4 hop.
Why does the Tor
Why does the Tor organization not create explosive growth in the network and development of Tor by making Tor a subscription service? This would destroy spammer/botnet abuse, relieve dependence on the US government for funding, create a huge development in the number and quality of relays, as well as fund all of these changes that are only being posed at this moment.
Subscriber anonymity can be preserved through bitcoin, so what reason is there not to do this?
As a user, I for one would
As a user, I for one would NOT use Tor if it cost money.
For me the reason would mainly be the same as why I ditched Ubuntu when they began with advertisement, that is, not compatible with open source ideals. But for some (many?) of Tor's target users I believe financial problems may be a bigger factor.
any additional commercial
any additional commercial service decrease anonymity. What the buzz about spammer/botnet - they add to YOUR anonymity. More various traffic means more costly to trace you. Let us-gov pay.
This clearly is a excellent
This clearly is a excellent way to boost the network and advance Tor, one can only wonder why the Torproject REFUSES FUNDING from anyone but the US gov and a few select entities.....
No, sorry, you cannot make a
No, sorry, you cannot make a conspiracy theory out of "Tor doesn't want to monetize their users." The conspiracy theory would go the other way around. :)
"conspiracy theory" is a
"conspiracy theory" is a negative stamp invented by government. There is conspiracy planing in government agencies. Terroristic actions against independent countries across the world are not "theory" but PLAN. Just like Marshall plan. Just like atomic bombing civil sites of Japan. And developers of these plans are very well paid "for their work".
If you do not develop strong
If you do not develop strong anti-botnet defenses, a few big botnets will break Tor or make it basically useless.
Concerning your remark about
Concerning your remark about Mike Perry, Adblocker and Google:
According to my experience Google answers already more that 80 % of the search requests via Tor with their sorry page. So having an adblocker in TBB will make the situation much worse. The first action a serious user will do after installing TBB is to download an adblocker.
use startpage.com or better
use startpage.com or better ddg.gg
Alas, the Google situation
Alas, the Google situation *can* get a lot worse. What if they start refusing to serve any content at all to Tor users -- even the static read-only stuff? No google news, google groups, google plus, all the other stuff they do.
So what? google == nsa, or
So what? google == nsa, or everybody already forget? Use Startpage.com as gateway to Google.com if you want, but to my opinion google.com useless. Many sites block access from Google robots bcose they don't want to feed it (NSA?). Surely if you search for common items like "where to buy this newest blue with silver border iPad (directly conneted to XXX)..." you'll be totally satisfed. Anyway you cant get uncensored results, and who are they to decide for you?
Is any search bring yiu NEW site, or its just habit and laziness to not enter https://torprogect.org but goggle it?!!!
A) Remember that google is
A) Remember that google is much more than just a search engine (as I tried to say above) and B) I cannot help but point out that torprogect.org won't get you where you wanted to go. :)
(All of this said, yes, yes, google is doing very poorly at their "don't be evil" goals these days. I'm not trying to say that we should all keep using Google. But I don't want to encourage *any* services to block Tor usage, because it's a slippery slope and we're already falling down it.)
Why any content ought to be
Why any content ought to be indexed by Google? You can block any access from Google to a restricted text documents with keywords (well, not all access ...).
Maybe it is poossible to distribute access to google.com across all TOr clients? I mean through tor bundle? Name it tor-bundle-google. Can anybody comment?
I remember there was some sort of random query generator to periodically ask google and potentially prevent user tracking.
To all the freedom lover and
To all the freedom lover and privacy fighter the Indonesia the no.1 thief nation on the web had urged the UN to make comprehensive anti privacy and whistle blower to the net. Which mean no more free speech and every thing must be under the Gov control. To all the Anonymous this your time to fight back against this country of thief and liar. Do that ASAP. Our enemy is not Russian or China it is Indonesia all along. They afraid the most against the free speech lover for something very stinky on their hidden place. So for Anonymous if you can find it or their then do that ASAP.
Your enemy IS YOUR
Your enemy IS YOUR government. They use your money to spy on you. Just think EVERY big country turn to dictatorship. And force their puppets do the same. Look at USA and UK.
Only operating or monitoring
Only operating or monitoring middle nodes provides a list of entry-exit pairs to query their respective ISP's logs for user-destination pairs.
If you assume that this automated process consumes too many resources for the small potential amount of interesting data it would yeild then:
1) Have a list of actionable domains. If someone visits, action may be taken.
2) Have a list of persons of interest.
3) Operate or moniter entry, middle and guard nodes.
4) If an exit detects a domain of interest of an entry detects an IP address that may belong to a person of interest then
a) Do I own the entry-exit pair (or the whole circuit if I can't tolerate false positives)? If so then I have an entry-exit pair.
b) Do I own the middle node? If so then I know the end I don't own. Automatically query the ISP to establish a entry-exit pair with their connection logs.
With the new 3.0 version of
With the new 3.0 version of TOR, there has to be added some way to get a "Network Map" like the current 2.X versions have.
I use that to monitor which connections are throwing up errors that I know they should not be (i.e. the node in question is doing filtering) so that I reason out "Okay, this happens when using X entry node and X exit node...... let's mark those as excluded and see what happens!"
I've done that with a lot of nodes in the past few weeks because they or their internet provider are doing filtering.
"letting users choose
"letting users choose different settings can make them more distinguishable"
would this even be true for a simple yes/no configuration (in this case: change unreachable guards fast/try to reconnect over some longish amount of time)?
I don't see a distinguishable changed usage pattern - though I'm neither a specialist in this area nor thought more in-depth about it.
Not only should tor users
Not only should tor users pick a limited set of entry nodes which they use, they should for similar reasons pick a limited set of exit nodes and a limited set of middle nodes which they use (although maybe the set of middle nodes can be bigger, because there's less chance of an attack there). And those sets should be non-overlapping.
The middle node is the best
The middle node is the best place to attack. It knows the IP address of both the entry and exit! You need a fourth node so that at least one end of the chain is onion routed. from any one point of failure.
I believe that the middle node is a single point of failure in the current Tor design.
You designers, contributors,
You designers, contributors, and enthusiasts amaze me. I commend you for thinking like the attacker. I admit I lack much background information and lack time to read past about 1/6th, but this is still incredible.
The problems with Tor and
The problems with Tor and always will be the problem until made better
HTTPS Everywhere
The problem is that it is so darn confusing and even if knew how to add sites is to complicated to do.
It needs to be fully automatic and non intrusive working away to protect the sites visited all with HTTP. If if cannot go to any site should instead show why it cannot do so.
Also I would think most of its problems with not been able to do so would be certificate related in one way or another. So should deal with that while ensuring that no data is saved to user computer.
TOR
Updates never to change current user layout, though saying this last update kept the layout hope this last longer than one update.
Reassure that server people connect to won't data harvest. I guess this is a bigger problem than Tor would like to admit but an issue non the less. This should be highlighted on main page don't do personal or financial transactions while using Tor.
Make Tor start faster every time as now sometimes can take forever and an age before the browser appears.
When browser launched on (about:blank page or default start page) that shows the current IP also to show the country of the IP. This is for many useful reasons not only knowing it is not from same country you are browsing from when don't need it.
A way to choose country easy and quicker than use map page page. Drop list to use IP from any country of choice
More guide how to use simply Tor with other applications and software's
The above is in no order and all are important for Tor future. This is so far seen when connected without bridges what ever that is. Nothing with Tor is easy to set up or use without knowledge no guides exist for this.
Remember the majority of Tor users (will be) are point and click users
Tor Portable (burn to* then boot from *cd or usb etc)
I did try the potable Tor thing once that I burn to cd and run from. But if cannot use the full screen what use is it. Wiki has some pages for pc monitor screen and their sizes such as this http://en.wikipedia.org/wiki/Display_resolution look at 'Most common display resolutions in the first half of 2012'
Code Tor portable to support all of those display resolutions would then make Tor portable more use-able than it is now
Roger's mention of
Roger's mention of browser-based exploits reminded me of a poorly-developed idea I once had for reducing Tor's attack surface in typical use cases:
What if relay operators could easily deploy something like a hidden service that allowed for something like VNC over SSH over Tor into sandboxed, user-verifiable, virtualized, ephemeral instances of Tails?
If there were a user-friendly way to direct users to this particular class of hidden services and for end-users to reliably verify the integrity of the Tails/Qubes instance they were using for browsing, it seems as though the attack surface--especially for browser-based exploits--could be significantly reduced. Packaging it up as something relay operators could easily deploy, reducing the per-instance computing resources required, and facilitating non-technical users' access seem like the main stumbling blocks. I know it's tough enough to get volunteers to run EC2 instances to relay traffic, but costs are still dropping pretty rapidly.
This doesn't mitigate many of the guard-related attacks Roger described, unfortunately, but I wanted to toss it into the comments anyway because of a somewhat-related personal habit of mine: If I'm a bit nervous about my use of Tor for everyday web browsing on monitored networks I don't control (e.g. at work or a coffee shop), I use VNC over SSH to access a trusted server running Tails in Virtualbox, which makes maintaining a (verifiably) known-good browser state easy.
LONG LIFE TO TOR PROJECT,EFF
LONG LIFE TO TOR PROJECT,EFF AND INTERNET DEFENSE LEAGUE!
What the internet world could be without them.
just wonder why this site is
just wonder why this site is not hidden service?
[ Tails OS ] uses one DNS
[ Tails OS ] uses one DNS server from OpenDNS.
What prevents a malicious party from signing up exit nodes at OpenDNS and logging traffic, blocking content, and/or redirecting traffic?
Please consider switching Tails' DNS to another provider in addition to adding more than one DNS IP, some service where nobody can sign up anonymously and possibly perform MITM attacks via DNS.
One reference:
https://lists.torproject.org/pipermail/tor-talk/2012-February/023272.ht…
"Single point of failure, OpenDNS could be forced to redirect DNS
requests for some unwanted websites to a trap. This means it should not be
used as a 100% DNS replacement for Tor."
Makes sense, but a comment
Makes sense, but a comment on a blog post about something different isn't going to get noticed by them. I suggest letting them know via their "found a problem?" page:
https://tails.boum.org/support/found_a_problem/index.en.html
From ISP it will be quite
From ISP it will be quite easy to distinguish Tor clients from any others. Permanently just one tcp connection to the same server/port. Why should we make it ease to track Tor users?
And it will disclose your
And it will disclose your bridge if any
You might like (or
You might like (or dislike)
https://blog.torproject.org/blog/research-problems-ten-ways-discover-to…
Thanks for your work on this
Thanks for your work on this project! I will look at linked topic.
Previous remark was not about status quo but if proposed change to one-relay-tcp-connection-forever make it easier for ISP (-level adversaries) to distinguish Tor client traffic and mark that client for further investigation. It is just ONE client ip - server ip (and server tcp port) record for months! No need in any packet analysis as it is basic IP-level info.
I think there are still
I think there are still quite a few other applications, like VPNs and ssh, that have a similar behavior. Heck, various google chat applications probably do as well. I wouldn't be too worried about this particular avenue (given all the things there are to worry about).
NO. You are not correct. At
NO. You are not correct. At least they use DNS service.
At that point I see one option to preserve current behavior - delete and reinstall Tor routinely. Why not think about adding some noise? False connections with random content? OK it may be another package anyway.
Let's assume I know a
Let's assume I know a trusted VPN that doesn't keep log, and let's say I use this configuration: me > tor >vpn
Since the connection between tor exit node and VPN is encrypted, an attacker that controls the entry guard and the exit node still can't find my IP nor attack me using a correlation attack. Is that correct?
In other words.. could a trusted and secure VPN as a permanent exit node help against an attacker who controls the entry guard (or ISP) and tor's exit node?
Thanks in advance and sorry for my english.
arma said: Check out
arma said:
Check out http://freehaven.net/anonbib/#ccs2011-trust for a paper that starts to explore the question of selecting your paths different from most users.
My current intuition is that for the specific config change you describe, you'll be harming your diversity (aka anonymity) a lot, for an unclear amount of gain.
Understanding the importance of the node/connection diversity, consider how easy for the NSA, etc., to copy and analyze ALL the US Internet traffic. Is that added diversity worth it if your traffic is plainly logged?
Suppose, since the Tor Project has/works with/relies on the US partners, they would not want to officially recommend this for everybody, but... for a poor single repressed user, isn't it still safer to exclude at least the US-based Tor nodes? :-)
When the high-snooping-risk countries, say, {US},{CA},{MX},{UK},{AU},{NZ},{DE},{IL},{RU},{CN} are excluded, Vidalia shows there is still a plenty - hundreds - of Tor nodes left in other countries. The snooping there, while present, would be harder/expensive to do on the same massive scale.
So what if there are no US-bound Tor connections. As for the lesser diversity, the country usage of each Tor user seems to be harder to track (especially once the US nodes are excluded). That would require looking at a majority of the Tor exit nodes worldwide.
Any thoughts? Anyone?
US exit nodes might help
US exit nodes might help someone in say kuwait. What are you suggesting, that they ban exits from operating in a certain country?
I believe it was supposed to
I believe it was supposed to give the user option to restrict his traffic to select countries. Maybe he/she knows better...
No, not suggesting to ban
No, not suggesting to ban any country system-wide - let the users decide. Rather, request your opinions: how much the statistical diversity of the US/UK/etc. nodes worth, if in practice they are supposedly fully accessible by NSA, all the time.
Asking this because:
- appreciate the arma's research, but his broad claim for connection diversity seems to ignore the recently confirmed all-time traffic recording in these few countries.
- Vidalia is going away, and one can't see the list of nodes in the Tor circuits, and can't see the error log easily.
- the ExcludeNodes command is "temporarily" and may be "discontinued" in the future.
(Yes, Tor devs, it would be invaluable to preserve the ability to see the list of circuit nodes, the error log, and the ExcludeNodes commands. Thanks.)
Half off-topic -no open
Half off-topic -no open Tails forum- but urgent:
The new TAILS 0.21 has DISABLED 'New Identity' with disabling the Control
Port. WTF.............?Sorry, iam a little bit upset
Is this really necessary?Or a failure?Or a joke?
How can i have the 'Newnym'-function(clear all caches,too) without closing
the browser?
Better reenable this function.Please.
The tails people will never
The tails people will never read this comment. You should tell them using the support channels they suggest:
https://tails.boum.org/support/index.en.html
While I appreciate the
While I appreciate the valiant effort of the Tor project, it seems to me that it's flawed in a very important way. That is that it may not ever do what aims to because....
The internet itself was a DARPA creation; designed not just to share data, but to track it. Trying to strip the tracking functionality is a bit like trying to make a a flying car out of a car when what we need is a plane. Or perhaps more accurately, making a mammoth Boeing 747 into a car, by ripping the wings off and attempting to make it smaller and road worthy. Just start from scratch.
I think what we need right now is an entirely new open source internet protocol with a focus built in security and anonymity. This is the challenge that the open source community must rise to, if freedom is to be retained/regained in the modern world.
This may sound daunting, but remember that the internet started with a handful of brilliant researchers and DARPA grants. With kickstarter and open source, we may be able to create a new protocol that works with existing hard/software and maybe the old web, but is automatically encrypted, anonymized, and free. I know people will say that Tor and open source encryption is getting there, but these are layers on an existing protocol designed to track everything. That is one of the main problems which Tor is made to solve, but it's a retro-fit. We need the web itself to be encrypted and anonymous.
I have a dream... where all men can access a new internet that is anonymous by nature, with end-to-end open source encryption built in...etc.
@arma
Good question. I'm no expert, but the way the NSA especially focuses on foreign communications and Tor means that some consideration may be warranted before preferring foreign Tor connections. It may not make much difference as they record everything regardless, or it may help, or it may make it worse.
So in summary, Tor is
So in summary, Tor is fundamentally flawed because it doesn't do this other thing that you wish somebody would work on?
The thing you want sounds great. It's also hard.
A simple way to increase an
A simple way to increase an attacker's False Positives for the question "Has Anne ever gone to Website X" is to occasionally give Anne a decoy website to visit. Anne's computer would request pages from the decoy website, but not bother displaying it to Anne. The decoy websites are chosen by the inner nodes and encrypted with a short lifetime public key generated by Anne, so the entry node does not know Anne's decoys. Then, if the attacker controls the entry node and Anne's browser visits X, then the attacker does not know if Anne (the person) intentionally visited X, or if X was a decoy.
Here is one way the inner node can choose decoy websites: The exit nodes learn many destination websites during normal operation. Each exit node can pass some of its destination websites back to the previous node in the chain as decoy candidates, and each inner node can pass a subset of its decoy candidates back to the previous node as decoy candidates. That way each node can build up a large list of decoy candidates.
Of course, an attacker could control an internal node, and give out fake decoys to their own website, so the attacker will see when the decoy is used. Does this help the attacker identify Anne? I don't know.
I've written a mail to the
I've written a mail to the dev-list,not published,but it's wasting time i think(-:.
If an for the user open Control Port is really a problem -is it??- OK.......
The one and only prefered from the TAILS develpers solution is close browser and open new browser.And ....maybe a port firewall in the future.
Annoying.
BUT there is a CATCH: Why every! new browser-opening opens a port to
check.torproject.org? WHY is this necessary??Curiosity?Can you logically explain this?
WITHOUT this......annoying useless? behaviour,closing/opening browser wouldn't
a problem.Can you help -delete 2 lines of code?
In the closed TAILS forum questions about this has had ignored with doggedness.
Another question:
in TBB there is no server list anymore(?).
You have wrote there would be no support for Vidalia.For Windows?
And for Linux? Tails has a server list.Have had...........?
You've wrote something like users could be confused to see more than one program.*LOL*that wasn't a lol for me only.Seriously?
Maybe i'am a little bit too skeptically but i've read the nsa-tor-papers meticulously -nsa try influencing the way tor gets developed,too.
Last question:
Could this a SIGINT problem if one EntryGuard,only one,has an Exit Node everytime from the same Family(icebeerFR.....) or is this normal?
Puh,a lot of questions(-:
So much crap coming out of
So much crap coming out of the torproject team these day I wonder how long it has left.
How about disable javascript by default, add the option 'Temporarily Allow site x' Instead of 'Allow script Globally', so newbies won't accidentally run those big brother services like those Google Analytics script.
In the Snowden 'Tor Stinks' power point release, they already mentioned you guys enabled javascript by default, and will use it against people, so what the fuck are you idiots waiting for?
Fix it or shut the fuck up about anonymity, how fucking hard is it to disable javascript by default.
Disabling javascript by
Disabling javascript by default will destroy usability -- it's the same reason no other mainstream browsers disable it by default.
https://www.torproject.org/docs/faq#TBBJavaScriptEnabled
The medium-term fix is
https://trac.torproject.org/projects/tor/ticket/9387
And the long-term fix is that Mozilla is working on better sandboxing for their browser (and/or we could sandbox it better by sticking it in a VM -- but how to do that without impacting usability too much remains an open question).
"So much crap coming out of
"So much crap coming out of the torproject team these day I wonder how long it has left"
disabled timecode in Cell Info with 0.2.4.18 is one step in right direction.
the next one could be really more jitter and fuzzing in data flow.
"...disabled timecode in
"...disabled timecode in Cell Info with 0.2.4.18..."
I havent read last detail in Tor protocol ,therefore(-: i have questions:
-Why is/was there a timestamp in CellInfo when it is not really necessary for client?NSA's last resort(-:
-If timestamp is not really necessary -in clients- why you don't scramble it randomly to obfuscate this till all Tor users use the new version?
And last, i hasn't understand the past discussion about "do not push the arm race". The ubiquitous survaillance was not really a secret before edward snowden was speaking.
Now you see the state is pushing this with force,therefore you must it,too.
Funny to see most mindless driveling"alu hat,aluhat,alu hat" is gone(-:.
Thank you Mr. Snowden